
+91 6002993949
submission@iarconsortium.org
Open Access
ISSN (Print) : 2788-9394
ISSN (Online) : 2788-9408
The objective of this research is to address the critical task of predicting complex equations in the fields of science, engineering and mathematics. To achieve this, the study investigates the effectiveness of Gradient Boosting, a powerful machine learning technique, in forecasting intricate problems. The primary novelty lies in leveraging coefficients from prior equations to facilitate learning and proposing new solutions based on practice data. The research utilizes Gradient Boosting to predict solutions for complex equations, incorporating well-known coefficient-form equations and their corresponding answers to instruct the algorithm. By doing so, the gradient-boosting regressor becomes adept at solving novel and challenging equations. To evaluate the model's predictive performance, various metrics, such as Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE) and R-squared (R2), are employed to measure the accuracy of its predictions. The study showcases the successful application of the trained model to solving equations and accurately predicting results. Researchers can assess the model's performance through a data frame, with all relevant data securely stored in a CSV file for further scrutiny and transparency. Furthermore, this work explores the versatile benefits and diverse applications of the gradient-boosting algorithm across various equation types. The research findings provide compelling evidence that the gradient-boosting approach can reliably anticipate complex equations with four variables. Given the widespread presence of intricate equation solutions in disciplines like math, physics and engineering, scientists widely adopt gradient boosting as a crucial tool to tackle these challenges effectively.
Predicting solutions to complex equations is paramount in several fields, including computer science, physics, engineering and mathematics. The ability to tackle intricate problems and draw intelligent conclusions can significantly impact research outcomes in these domains [1].
The complex equations encountered in these fields often involve multiple variables and nonlinear interactions, challenging traditional analytical techniques. Developing accurate and efficient computational tools for modeling and predicting these solutions is essential to advancing scientific understanding and engineering innovations.
The technique of Gradient Boosting demonstrates simplicity, potency and dependability in determining the exact solutions of complex equations [1]. Its broad applicability is evident in various scientific disciplines, including nonlinear optics, fluid mechanics, laser physics and plasma physics, where complex events are carefully solved to understand their nature and improve physical mechanisms [2]. Gradient Boosting offers advantages in solving nonlinear partial differential equations, including weakly singular integral solutions and lattice Toda equation solutions, ending its utility to complex nonlinear applied science issues [2,3].
The results of using Gapplyingn to solve complicated equations have proven promising. Condensed formulations accurately forecast propagative, transient and complicated wave solutions while reducing computational time significantly [4]. Most nonlinear partial and fractional differential equations that arise in difficult conditions can be precisely solved using this technique [5]. Additionally, this approach exhibits applicability and dependability in addressing the complexities presented in research problems [5,6], with potential extensions to more intricate geometries and nonlinear physical systems.
By leveraging minimal data generated from equation solutions, the Gradient Boosting Algorithm accurately predicts flow parameters in porous media while significantly reducing calculation time [7]. Its ease of application, in contrast to conventional solutions, makes it a valuable tool that does not rely on the theory of functions of a complex variable [8]. Furthermore, the presented approach facilitates the rapid identification of exact constitutive equations from sparse data, enabling better explanations of intricate kinematic processes [9].
In machine learning, the effectiveness of Gradient Boosting has been demonstrated through its application to various regression and classification tasks [10,11]. Ensembles of Gradient Boosting models have consistently outperformed other methods, thanks to the vast range of adjustable loss functions and hyperparameters, rendering the algorithm more accurate and flexible [12].
The adaptability of Gradient Boosting to handle mixed, categorical and numerical predictor variables further enhances its utility in solving equations with diverse variable types [13]. It differs from other "black-box" machine learning methods in that the algorithm is interpretable. Understanding the relative importance of the various parts offers important new perspectives on the intricate interrelationships seen in equations [14]. Overall, the Gradient Boosting method proves to be a potent tool for precisely anticipating solutions to complex problems. Its capacity to manage complex relationships, handle diverse variable types and offer interpretable results makes it indispensable for tackling challenging equation-solving problems across different scientific and engineering domains.
This study addresses the research problem of modeling and predicting solutions to complex equations in computer science, physics, engineering and mathematics. Given the challenges posed by the complexity of these equations and their nonlinear interactions, traditional analytical techniques may be insufficient [15]. Therefore, developing accurate and efficient computational tools, like the Gradient Boosting Algorithm, becomes essential to advance scientific knowledge and practical applications [16].
The main objectives of this study are to design a Gradient Boosting Algorithm, apply it to model complex equations found in various scientific fields, predict solutions for new equations, evaluate its performance against traditional methods and explore practical applications for the developed techniques. This work aims to provide valuable insights into modeling and predicting solutions to complex equations across a wide array of scientific and engineering contexts by addressing these research aims. The study contributes computational methodologies to efficiently handle intricate equation solutions and foster further advancements in related fields.
The research presents a vital resource for handling challenging equations, showcasing the efficiency and broad applicability of the Gradient Boosting Algorithm. The significant implications of its performance in solving complex equations provide promising opportunities for advancements in mathematics, physics and engineering. As researchers and practitioners address complex equation-solving tasks, this study offers a crucial tool to empower their endeavors.
The paper is structured as follows: Section 2 provides a theoretical review; Section 3 discusses the benefits and drawbacks of the Gradient Boosting algorithm in solving complex equations; Section 4 introduces evaluation metrics to assess the effectiveness of the algorithm; Section 5 presents the findings and discussion from the experimental analysis; and finally, Section 6 concludes the study.
The authors introduced a hybrid spectral-conjugate gradient technique for approximate solutions to nonlinear monotone operator equations that restore damaged signals in 2021 [17].
In the same year, principle component regression had 95% prediction accuracy and Gradient Boosting classification had 100% classification accuracy. This performance was comparable to state-of-the-art models [18].
In Zharmagambetov et al. [19] another research project developed a gradient-directed line search technique for nonlinear systems of equations. This approach minimized iterations and function evaluations and showed numerical efficiency.
In the same year, empirical data demonstrated that the model outperformed Gradient boosting and AdaBoost on several benchmarks in accuracy and model size [20].
In 2021, researchers found that the boosting technique enhanced the CART model's accuracy and precision. However, the boosting approach took 2 minutes to fit the model [21].
The authors produced global convergence of the forms and gave two optimal possibilities for the Hager-Zhang conjugate gradient method's non-negative constant in the same year. Computations resolved massive monotone nonlinear equations efficiently [22].
A 2021 comparison showed that gradient-boosting-based regression outperformed random forest regression, bagging and regression trees [23].
Finally, in 2021, gradient-boosting regression outperformed other machine-learning models [24].
Artificial neural networks (ANNs) and gradient-boosted trees excelled in most instances in 2022. Gaussian process surrogates are the most commonly used surrogate modeling approach for complicated computational models [25].
Contribution of the article to related work The Gradient Boosting Algorithm is essential for scientists and engineers who must solve complex equations. This theory advances mathematics, physics and engineering research due to its high prediction accuracy and broad applicability. This study offers academics and practitioners a powerful computational tool for performing complex mathematical assignments to tackle challenging scientific problems. The theoretical overview, algorithm analysis, evaluation metrics, experimental findings and practical implementations add to a complete method for modeling and predicting complicated equation solutions.
Advantages and Limitations of the Gradient Boosting Algorithm
A potent machine learning approach called gradient boosting has significant benefits over traditional statistical models for time series data, such as ARMA. Its superior performance to these conventional models, particularly in capturing intricate patterns like holidays [26], is a noteworthy benefit. Because of this, it is a better option for working with time series data that exhibit periodic or seasonal fluctuations.
An improved classification technique that uses decision trees called the Light Gradient Boosted Machine (LightGBM) has been successful for a number of tasks. With a precision score of 93%, a recall score of 93% and a Mathew's Correlation coefficient score of 0.91 [27], it produced remarkable results in a specific application. These impressive performance figures show how well it can handle challenging categorization jobs.
Gradient Boosting's capacity to optimize sub-models in a manner that enables them to extract discriminant information complementarily and non-redundantly is one of its strengths [28]. As a result, the total prediction capacity of the algorithm is increased since each sub-model concentrates on a different component of the data.
Although Gradient Boosting performs remarkably, it is important to take into account its limits. For instance, research has shown that the Extreme Gradient Boosting (XGBoost) method, a well-known variation of Gradient Boosting, has the greatest performance results [29]. However, it could have certain negatives, such as increased time and resource demands. When choosing a suitable algorithm, it is important to carefully take the resources that are available and the application's needs into account.
In conclusion, Gradient Boosting is a useful technique that performs better than traditional statistical models in detecting intricate patterns in time series data. Effective discriminant information extraction is made possible by its sub-model optimization. The outstanding performance of the LightGBM version in certain applications demonstrates that it is especially well-suited for classification jobs. But, particularly for algorithms like XGBoost [30], it is vital to weigh their benefits against latency and resource allocation issues.
Metrics to Assess the Performance of the Algorithm
Mean Squared Error (MSE): A statistic that illustrates the average squared difference between actual and anticipated values. It measures the model's accuracy, with lower numbers indicating more excellent performance [31]
Root Mean Squared Error (RMSE): This metric, the square root of Mean Squared Error (MSE), provides a more intelligible measurement in the same units as the target variable [31,32]
Mean Absolute Error (MAE): MAE calculates the average absolute variation between the observed and predicted values. It is less susceptible to outliers than MSE [31,33]
R-squared (R2): R-squared demonstrates how much of the variation of the target variable can be predicted from the features supplied as input. Higher values suggest a better fit of the model to the data; the scale runs from 0 to 1 [34]
Explained Volatility Score: This metric calculates the proportion of the target variable's volatility that the model can explain. The model's goodness of fit can also be evaluated in this manner [35]
Mean Absolute Percentage Error (MAPE): MAPE determines the typical percentage difference between the actual and forecasted values. About the size of the target variable, it aids in understanding how accurate predictions are use of scikit-learn library in python to get these evaluation metrics because it has functions for computing them. Predict the answers to the equations by fitting the gradient-boosting regression model. After comparing the projected and actual solutions, utilize the evaluation metrics to determine the model's performance
The proposed methodology, outlined in pseudocode, utilizes the Gradient Boosting algorithm for symbolic regression tasks. Symbolic regression involves finding the coefficients and constants that best fit a set of equations and the interpretability of the algorithm distinguishes it from other black-box machine learning techniques. Here is a step-by-step explanation of the methodology. Using various variables and equations, the metrics to assess the performance of the algorithm are put into practice:
Import necessary libraries: numpy, pandas, sympy, sklearn. Ensemble (Gradient Boosting Regressor) and learn.metrics (mean_squared_error, mean_absolute_ error, r2_score)
Define the variable symbols (x1, x2, x3, x4) using sympy
Define the equations using the Sympy Eq() function and store them in a list called "equations"
Create empty lists "X" and "y" to store the coefficients and constants of the equations, respectively
Iterate through each equation in "equations"
Extract the coefficients and constants from each equation using Simpy's Coeff function
Append the coefficients to the list "X" and the constant to the list "y"
Convert lists "X" and "y" into numpy arrays
Create a GradientBoostingRegressor model and store it in the "regressor" variable
Fit the GradientBoostingRegressor model using the "X" and "y" data
Use the trained model to predict the solutions for the equations and store the indicated keys in "predicted_solutions"
Calculate the evaluation metrics
Calculate the Mean Squared Error (MSE) between the actual and predicted solutions using mean_squared_error()
Calculate the Root Mean Square Error (RMSE) by taking the square root of MSE
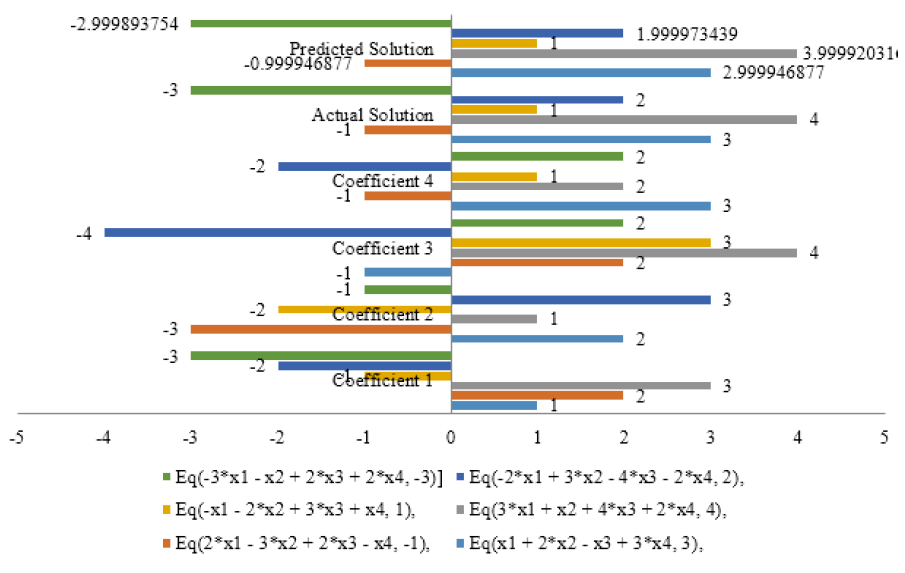
Figure 1: Bar Graph Comparison of Real and Expected Complex Equation Solutions
Table 1: Four-Variable Equations and Their Coefficients, Actual Solution, and Predicted Solution
Equation | Coeff. 1 | Coeff.2 | Coeff.3 | Coeff.4 | Actual Solution | Predicted Solution |
Eq(x1 + 2*x2 - x3 + 3*x4, 3) | 1 | 2 | -1 | 3 | 3 | 2.99 |
Eq(2*x1 - 3*x2 + 2*x3 - x4, -1) | 2 | -3 | 2 | -1 | -1 | -0.99 |
Eq(3*x1 + x2 + 4*x3 + 2*x4, 4) | 3 | 1 | 4 | 2 | 4 | 3.99 |
Eq(-x1 - 2*x2 + 3*x3 + x4, 1) | -1 | -2 | 3 | 1 | 1 | 1 |
Eq(-2*x1 + 3*x2 - 4*x3 - 2*x4, 2) | -2 | 3 | -4 | -2 | 2 | 1.99 |
Eq(-3*x1 - x2 + 2*x3 + 2*x4, -3) | -3 | -1 | 2 | 2 | -3 | -2.99 |
Calculate the Mean Absolute Error (MAE) between the actual and predicted solutions using mean_absolute_error()
Calculate the R-squared (R2) score between the actual and predicted solutions using r2_score ()
Display the evaluation metrics (MSE, RMSE, MAE and R2) using print function
Create an empty list of "results" to store the solutions and predicted solutions for each equation
Iterate through each equation in "equations"
Extract the coefficients and constants from each equation using Sympy's coeff function
Use the trained model to predict the solution to the current equation using the coefficients
Append the coefficients, constants and predicted solution to the "results" list
Create a pandas DataFrame "df" from the "results" list, with columns: "Coefficient 1", "Coefficient 2", "Coefficient 3", "Coefficient 4", "Actual Solution," and "Predicted Solution"
Save the DataFrame "df" as a CSV file named "equation_results.csv" using df.to_csv
Display a message indicating that the equation results have been saved in the CSV file
To compare results across multiple categories, a bar chart with varying distances is utilized. This chart is very useful when dealing with extensive category labels or durations. Let's now connect it to the code's equations and results. In Table 1, where four-variable equations are solved using the same methodology. And the Bar Graph Comparison of Real and Expected Complex Equation Solutions in Figure 1.
The provided code successfully solves complex equations with four variables (x1, x2, x3, and x4) and their coefficients using the Gradient Boosting algorithm. The process is explained, and the relevance of each step is highlighted. SymPy is employed to define and convert the equations into coefficient form. The feature matrix (X) is created by extracting the coefficients.
In conclusion, the study confirms the effectiveness and reliability of the Gradient Boosting algorithm for predicting solutions to complex equations. Its ability to learn from known equations and generalize to new problems highlights its potential for solving challenging mathematical, scientific, and engineering problems. This research opens up new avenues for utilizing machine learning techniques in various fields that deal with intricate mathematical relationships. In conclusion, the Gradient Boosting algorithm proves to be an effective tool for solving complex equations. Its accuracy, as demonstrated through the bar chart representation of results, allows for accurate modeling and prediction of solutions. This approach is precious in scientific and engineering fields where traditional analytical methods struggle to obtain exact solutions.
Kaewta, S. et al. “Explicit Exact Solutions of the (2+1)-Dimensional Integro-Differential Jaulent-Miodek Evolution Equation Using the Reliable Methods.” International Journal of Mathematics and Mathematical Sciences, 2020.
Odabasi, M. “Traveling Wave Solutions of Conformable Time-Fractional Zakharov-Kuznetsov and Zoomeron Equations.” Chinese Journal of Physics, vol. 64, 2020, pp. 194-202. https://doi.org/10.1016/j.cjph.2019.11.003.
Hamid, M. et al. “Hybrid Fully Spectral Linearized Scheme for Time-Fractional Evolutionary Equations.” Mathematical Methods in the Applied Sciences, vol. 44, 2020, pp. 3890-3912. https://doi.org/10.1002/mma.6996.
Osman, M. et al. “Investigating Soliton Solutions with Different Wave Structures to the (2+1)-Dimensional Heisenberg Ferromagnetic Spin Chain Equation.” Communications in Theoretical Physics, vol. 72, 2020. https://doi.org/10.1088/1572-9494/ab6181.
Gao, F. et al. “Analytical Treatment of Unsteady Fluid Flow of Nonhomogeneous Nanofluids among Two Infinite Parallel Surfaces: Collocation Method-Based Study.” Mathematics, 2022. https://doi.org/10.3390/math10091 556.
Kamrava, S. et al. “Simulating Fluid Flow in Complex Porous Materials by Integrating the Governing Equations with Deep-Layered Machines.” NPJ Computational Materials, vol. 7, 2021. https://doi.org/10.1038/s41524-021-00598-2.
Matrosov, A. et al. “Method of Initial Functions and Integral Fourier Transform in Some Problems of the Theory of Elasticity.” Zeitschrift für angewandte Mathematik und Physik, vol. 71, 2020, pp. 1-19. https://doi.org/10.1007/ s00033-019-1247-3.
Chu, Y. et al. “Application of Modified Extended Tanh Technique for Solving Complex Ginzburg-Landau Equation Considering Kerr Law Nonlinearity.” Computers, Materials and Continua, 2021. https://doi.org/10.32604/cmc.2020. 012611.
Lennon, K. et al. “Scientific Machine Learning for Modeling and Simulating Complex Fluids.” arXiv, 2022. https://doi. org/10.48550/arXiv.2210.04431.
Ustimenko, A. et al. “Uncertainty in Gradient Boosting via Ensembles.” arXiv, 2020.
Cai, J. et al. “Prediction and Analysis of Net Ecosystem Carbon Exchange Based on Gradient Boosting Regression and Random Forest.” Applied Energy, vol. 262, 2020. https://doi.org/10.1016/j.apenergy.2020.114566.
Toghani, T. and G. Allen. “MP-Boost: Minipatch Boosting via Adaptive Feature and Observation Sampling.” Proceedings of the IEEE International Conference on Big Data and Smart Computing, 2021, pp. 75-78. https://doi.org/10.1109/ BigComp51126.2021.00023.
Adnan, A. et al. “A Comparison of Bagging and Boosting on Classification Data: Case Study on Rainfall Data.” Journal of Physics: Conference Series, vol. 2049, 2021. https://doi. org/10.1088/1742-6596/2049/1/012053.
Chavez, G. et al. “Scalable and Memory-Efficient Kernel Ridge Regression.” Proceedings of the IEEE International Parallel and Distributed Processing Symposium, 2020, pp. 956-965. https://doi.org/10.1109/IPDPS47924.2020. 00102.
Yoon, J. “Forecasting of Real GDP Growth Using Machine Learning Models: Gradient Boosting and Random Forest Approach.” Computational Economics, vol. 57, 2020, pp. 247-265. https://doi.org/10.1007/s10614-020-10054-w.
Abubakar, A. et al. “A New Hybrid Three-Term Spectral-Conjugate Gradient Method for Finding Solutions of Nonlinear Monotone Operator Equations.” Mathematics and Computers in Simulation, vol. 201, 2021, pp. 670-683. https://doi.org/10.1016/J.MATCOM.2021.07.005.
Khan, M. et al. “Water Quality Prediction and Classification Based on Principal Component Regression and Gradient Boosting Classifier Approach.” Journal of King Saud University-Computer and Information Sciences, vol. 34, 2021, pp. 4773-4781. https://doi.org/10.1016/J.JKSUCI.2021. 06.003.
Hashim, K. and M. Shiker. “Using a New Line Search Method with Gradient Direction to Solve Nonlinear Systems of Equations.” Journal of Physics: Conference Series, vol. 1804, 2021. https://doi.org/10.1088/1742-6596/1804/1/012 106.
Zharmagambetov, A. et al. “Improved Multiclass AdaBoost for Image Classification: The Role of Tree Optimization.” Proceedings of the IEEE International Conference on Image Processing, 2021, pp. 424-428. https://doi.org/10.1109/ ICIP42928.2021.9506569.
Zhao, L. et al. “Decision Tree Application to Classification Problems with Boosting Algorithm.” Electronics, 2021. https://doi.org/10.3390/electronics10161903.
Sabi’u, J. et al. “A Modified Hager-Zhang Conjugate Gradient Method with Optimal Choices for Solving Monotone Nonlinear Equations.” International Journal of Computer Mathematics, vol. 99, 2021, pp. 332-354. https://doi.org/ 10.1080/00207160.2021.1910814.
Dahiya, N. et al. “Gradient Boosting-Based Regression Modeling for Estimating the Period of the Irregular Precast Concrete Structural System.” Journal of King Saud University-Engineering Sciences, 2021. https://doi.org/10. 1016/j.jksues.2021.08.004.
Bhamare, D. et al. “A Machine Learning and Deep Learning-Based Approach to Predict the Thermal Performance of Phase Change Material Integrated Building Envelope.” Building and Environment, 2021. https://doi.org/10.1016/ J.BUILDENV.2021.107927.
Angione, C. et al. “Using Machine Learning as a Surrogate Model for Agent-Based Simulations.” PLoS ONE, vol. 17, 2022. https://doi.org/10.1371/journal.pone.0263150.
Thomas, J. et al. “Gradient Boosting for Distributional Regression: Faster Tuning and Improved Variable Selection via Noncyclical Updates.” Statistics and Computing, vol. 28, 2018, pp. 673-687. https://doi.org/10.1007/s11222-017-9754-6.
Persio, L.D. and N. Fraccarolo. “Energy Consumption Forecasts by Gradient Boosting Regression Trees.” Mathematics, 2023. https://doi.org/10.3390/math1105 1068.
Kumaran, S. et al. “Automated Classification of Chandra X-Ray Point Sources Using Machine Learning Methods.” Monthly Notices of the Royal Astronomical Society, 2023. https://doi.org/10.1093/mnras/stad414.
Gellert, A. et al. “Estimation of Missing LiDAR Data for Accurate AGV Localization.” IEEE Access, vol. 10, 2022, pp. 68416-68428. https://doi.org/10.1109/ACCESS.2022.318 5763.
Li, B. et al. “Assembling Global and Local Spatial-Temporal Filters to Extract Discriminant Information of EEG in RSVP Task.” Journal of Neural Engineering, vol. 20, 2023. https://doi.org/10.1088/1741-2552/acb96f.
Hodson, T. “Root-Mean-Square Error (RMSE) or Mean Absolute Error (MAE): When to Use Them or Not.” Geoscientific Model Development, 2022. https://doi.org/10. 5194/gmd-15-5481-2022.
Ding, R. et al. “Radar Target Localization with Multipath Exploitation in Dense Clutter Environments.” Applied Sciences, 2023. https://doi.org/10.3390/app13042032.
Anisha, C.D. and N. Arulanand. “Tuned Homogenous Ensemble Regressor Model for Early Diagnosis of Parkinson Disorder Based on Voice Features Modality.” Journal of Artificial Intelligence and Capsule Networks, vol. 4, no. 3, 2022, pp. 188-199. https://doi.org/10.36548/jaicn.2022.3.005.
Valbuena, R. et al. “Evaluating Observed versus Predicted Forest Biomass: R-Squared, Index of Agreement or Maximal Information Coefficient?” European Journal of Remote Sensing, vol. 52, 2019, pp. 345-358. https://doi.org/10. 1080/22797254.2019.1605624.
Makki Mohialden, Y. et al. “Recent Hybrid Machine Learning Algorithm Applications: A Review.” Journal of Information Technology and Informatics, vol. 2, no. 1, 2022, pp. 1-4.
Reza, R. and S. Pulugurtha. “Forecasting Short-Term Relative Changes in Travel Time on a Freeway.” Case Studies on Transport Policy, 2019. https://doi.org/10.1016/J. CSTP.2019.03.008.
