
+91 6002993949
submission@iarconsortium.org
Open Access
ISSN (Print) : 2788-9394
ISSN (Online) : 2788-9408
Recently every scenario involving authentication and identification, biometric security assurance is essential. Due to eye iris stable and remarkable texture variation, iris recognition is thought to be the most trustworthy biometric recognition and iris recognition is used to identify those who need a high level of security. Generally, seven phases are included in recognition system: the acquisition phase, the preprocessing phase, the segmentation phase, the normalization phase and finally feature extraction phase. The development of artificial intelligence offers a fantastic potential to expand the use of iris recognition for protecting people's personal information and convolutional neural networks are a useful method that are well suited for pattern recognition and image processing because of their efficiency and adaptability. The purpose of current study is to develop a high-accuracy system for person identification from eye iris using a convolutional neural network CNN. The suggested method has been effectively put into practice by using three datasets. The deep recognition algorithm is trained using iris samples from these datasets that contain 50 different people, including data from both eyes. The results amply the effectiveness of the experimental evaluation on iris images especially from the AMF dataset, where the trained model was successful in achieving 98.46% testing accuracy.
One of the key components of the security system is personal identification. Recently, Biometric systems have grown more important to the operation the system of security. The term "biometric" denotes to the quantifiable examination of biological traits which utilized in a variety of applications for person identification, including e-commerce, the military, communication, etc. These quantifiable characteristic is known as a biometric and it might be behavioral or physical. Behavioral, like a signature or beat writing and physical, like a face, iris, distinctive fingerprint, hand geometry or speech [1,2].
Nowadays, technology has evolved into an essential component of every person. Traditional identification techniques are ineffective where the majority of these techniques are vulnerable to theft, loss, forgetfulness, damage and hacking, including credit cards, identification cards and even passports. As a result, it is now necessary to develop safer and more dependable alternatives to the old systems, which allow for the storage of money and documents but are invulnerable to hacking. Biometrics can provide this level of security for identification and authentication because each individual has unique features and characteristics that no two people could possibly share. Examples include the lines in a fingerprint, the voice signal, measurements of the face, the features and iris characteristics [3].
The iris is one of the internal organs of the human body, it is a rotund, colored fragment of the human eye which protected by the cornea and the eyelid, by regulating the pupil's diameter and size, eye regulates the quantity of the iris of the human light that reaches the retina. Iris is one of the most significant biometrics which utilized for security issues due to its uniqueness and stability over time and also considered the most dependable security methods in recent years is iris-based recognition [4].
The techniques utilized for feature extraction, classification and feature recognition are what will determine how robust a system will be, as well as how fast and accurate it will be. Deep learning can meet these requirements, deep learning allows the system to automatically extract features, classify and discover patterns without explicitly programming them and many research has started employing deep learning in their approaches. Object detection and face recognition are two examples of patterns recognition based on deep learning, also deep learning applied in the iris recognition system, where numerous researchers employed deep learning to address issues with segmentation, recognition and classification [5].
Deep CNN-supported learning techniques have recently made incredible advancements in both computer vision and pattern recognition applications. For a range of difficulties associated to the assignment and catching biometrics, deep learning-based strategies have produced resounding results. Convolutional neural networks (CNNs), a subset of artificial intelligence, are capable of learning and extracting characteristics automatically in a manner similar to that of a human, by contrast, traditional neural networks are unable to learn features automatically [6].
In this study, we will look at an iris recognition system that separates the iris from other eye structures, such as the eyelid and lashes and then uses a deep convolutional neural network to extract characteristics to identify the person based of iris features. The following section presents related works to iris segmentation, in section 3 the methodology of the work is introduced followed with experimental results in section4 and finally section 5 introduced the conclusion.
Related Work
Le et al. [7] presented a method for iris segmentation that combines learning-based and edge-based algorithms. To find and categorize the eye, a well-designed Faster R-CNN with only six layers is created. A Gaussian mixture model is used to locate the pupillary area using the Faster R-CNN's discovered bounding box. The pupillary region's circular boundary is then fitted using five crucial boundary points. The circular border of the limbus is formed utilizing the boundary points that were discovered using a boundary point selection technique. On the difficult CASIA-Iris-Thousand database, experimental findings revealed that the suggested iris segmentation approach obtained 95.49% accuracy.
Ahmadi et al. [8] proposed the extravagant iris recognition methods that are based on combination of two dimensional Gabor kernel (2-DGK), Step Filtering (SF) and Polynomial Filtering (PF) for feature extraction and hybrid Radial Basis Function Neural Network (RBFNN) with Genetic Algorithm (GA) for matching task. To assess the performance of the proposed method, they used two benchmarks in their algorithm and implemented it on CASIA-Iris V3, UBIRIS. V1 and UCI machine learning repository datasets. The experimental results of the proposed method reveal that the method is efficient in the iris recognition.
Chang et al. [9] suggested a brand-new iris segmentation method based on active contour. Their strategy makes use of cutting-edge algorithms, including two crucial ones: calculation of the iris circle and pupil segmentation. Their method allows to precisely segment the iris and determine the pupil's center position and radius. Their suggested strategy has a 92% accuracy rate for the ICE dataset and a high level of 79% accuracy for UBIRIS dataset.
Omran and AlShemmary [3] proposed IRISNet system which automatically extracts features and classes without the use of domain knowledge. IRISNet's architecture comprises of Softmax and Convolutional Neural Network layers for feature extraction and classification into N classes, respectively. For CNN training, the backpropagation algorithm and Adam optimization approach are used to update the weights and learning rate. Using the IITD V1 iris database, the proposed system's performance was assessed. The suggested system outperforms supervised classification models (SVM, KNN, DT and NB) in terms of outcomes. For the original and normalized photos, the identification rates were 97.32 and 96.43%, respectively.
Sardar et al. [10] created a unique deep ISqEUNet model with interactive learning in an imperfect environment. By lowering the amount of trainable parameters, the Squeeze-Expand module increased network training speed while also improving segmentation accuracy. Particularly when there were inadequate annotations available, robustness in iris segmentation was enabled by fine-tuning for interactive learning. The findings of segmentation were compared to those of cutting-edge iris segmentation approaches. Results from databases including CASIA-Irisv4-Interval, IITD and NICE.I demonstrated their algorithm's superiority for less-than-ideal iris images using the evaluation metrics MER, DSC and mTPR. According to experimental findings, iris images acquired in the visible and near-infrared spectrums, including those of uncooperative and imperfect samples, may be appropriately segmented with ISqEUNet without the need for any laborious pre- or post-processing. In comparison to approaches, the mean error rate demonstrated at least a 0.4% improvement.
Therar et al. [11] Depending on the architecture of a deep learning model for images of a person's (right & left) irises, a multimodal biometric real-time technique is suggested. The features of transfer learning methods and convolution neural network characteristics have been combined to create this system. Through this research, the back-propagation technique was the training system of choice, with Adam's optimization approach being employed to change weights and alter learning rates as the learning process progressed. After training, the developed system provides accuracy of 99% for both the left and right IITD iris datasets as well as (94 and 93%) for the left and right iris for the CASIA-iris-V3 interval datasets.
Generally, the iris recognition system consists of the following successive steps presents in Figure 1:
Image Acquisition
Pre-processing
Iris segmentation
Iris normalization
Feature extraction and Classification
Image Acquisition
Typically, the visible or near-infrared (NIR) spectrums are used to capture an image of the iris. Lighting, lens, sensor and console make up the four components for iris image acquisition. Instead of the iris' pigmentation, images taken in the NIR spectrum often interact with the region's intricate texture. Additionally, iris image acquired with the NIR are less susceptible to various types of noise than iris photographs taken with the visible spectrum. Approach improves the performance effectiveness of iris identification by enabling the iris texture to be captured even with dim colors. While some databases of iris images were taken by the visible wavelength (VIS) spectrum, the NIR spectrum was used to collect the majority of the databases. The iris images are kept in both compressed and uncompressed versions in the databases [12]. A data collection called (AMF Iris dataset) was produced by researcher AHMED MYASAR FATHI. Given that it was made freely available to all academics; this data set effectively contributes to enhancing the scientific side of the study of identifying individuals through the iris of the eye. The 540 samples were taken by the iris scanner (VistaEY2H), which uses many wavelengths of infrared light to capture the iris. The volunteers' ages ranged from 20 to 40 and there were 54 of them. Both sexes, with 5 samples for each iris and 10 samples per participant. The acquired images with a resolution of (640×480) pixels are saved in Bitmap File Format (BMP). The database was set up and kept in 54 directories that corresponded to 54 individuals. Ten images total, five of the left and five of the right eyes, are included in each folder [13].
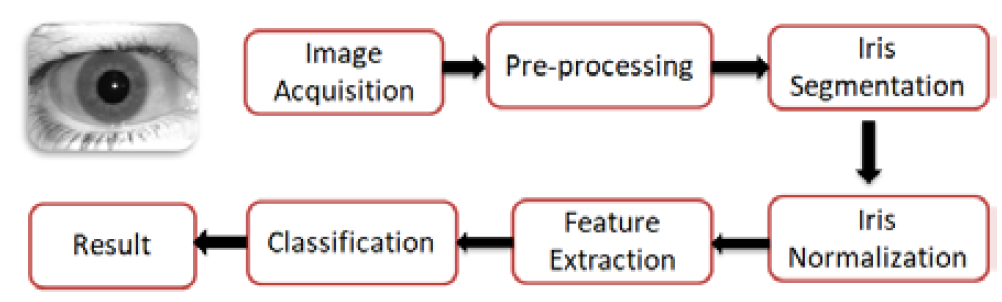
Figure 1: Main Steps Included in Iris Recognition System [12]
Preprocessing Image
The first phase in recognition system is a preprocessing. This step can aid in the elimination of the various noise types that occurred through the acquisition of the iris image. The noise that is typically present in iris images includes blurring, specular reflections, scratches and other elements induced by eyeglasses, lighting or illumination, closing from the eyelids or eyelashes, distortion and off-angle iris. The preprocessing stage will improve the IRS's performance accuracy by eliminating this kind of noise [14].
Different devices will result in different images acquisition and thus differences in the images of the iris of the eye. So, the objective of preprocessing phase is to improve information, reduce noise and simplify data in iris photographs. Image smoothing, edge detection, image categorization and other procedures are typically included in the preprocessing process [15].
Grayscale
Grayscale conversion of color images is done to speed up image processing. The 24-bit RGB input model image is transformed into an 8-bit grayscale image with a value between 0 and 255 [16]. Figure 2(a, b) displays a color image of the iris and the same image in grayscale.
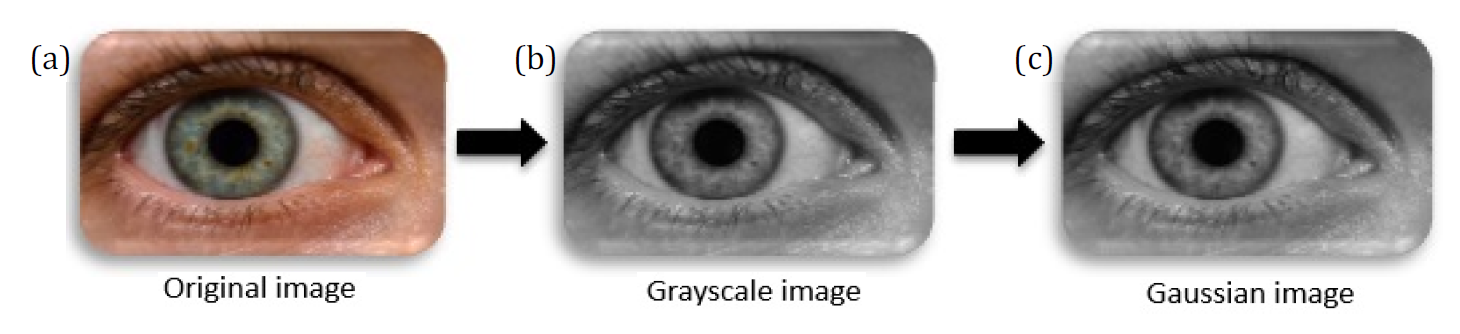
Figure 2: Pre-Processing for Iris Recognition System (IRS)
Gaussian Filter
Noise is a common component of digital photographs. Therefore, an image filter must be used to smooth the image before analysis and this can be achieved by modifying nearby pixels. The image is smoothed out and the angular shapes of the items are preserved thanks to the filter design [17].
A Gaussian filter is performed to eliminate the noise in eyes images. Gaussian filter is a linear smoothing filter that allows for the smoothing of noise by blurring the original image. The 2D kernel of Gaussian filter is performed on the original image. As the distance from the kernel center increases, the Gaussian kernel coefficients decrease. Additionally, the values in the kernel's center are given more importance than those towards its margins. The first step is to remove the effect of artifacts in the image of the eye, where a Gaussian filter with a mask size of (7*7) is applied to smooth the entire image of eye. Equation 1 shows the Gaussian filter [18].
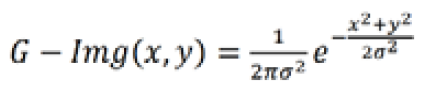
where, F is the distribution's standard deviation. The blurring is more pronounced the higher the value of F. This step's outcome is depicted in Figure 2c.
There are many factors, including motion of persons, the camera type and optical wavelength used to capture the eye images, the relative ambient light intensity in the backdrop, occlusive interference from eyelids and eyelashes, can negatively effect on iris recognition performance [19].
Iris Segmentation
The primary stage in fully recognizing the iris is segmentation. Its goal is to separate the functional iris pattern from other ocular structures and background noise.

Figure 3: The Suggested Methods for Iris Segmentation
Future treatment outcomes will be significantly impacted by how precisely the iris is split [20]. From another perspective iris segmentation is eliminate the eyelids and eyelashes from the input eye image, for leaving only the iris to be used as an input for the feature extraction process [21]. In this section, we will describe the suggested approach, which begins with the isolation of eyelid and lash regions and detection of pupil and iris boundary regions. Implementing an algorithm for autonomously segmenting the iris region from an eye image is a vital step in iris recognition systems. Two circles are drawn around the iris region; the inner circle denotes the pupil boundary and the outer circle the iris boundary [22]. In this study, the circular iris and pupil regions have been localized and the iris region has been segmented using the Hough transform and canny edge detection, where two circles-one for the pupil/iris boundary and other for the iris/sclera boundary-can be used to represent the region of the iris. First, Edge detection using canny operator is applied: canny edge detection is used to determine the edges of the eye image [23]. Since the Canny method can maintain a low error rate, preserve useful information by removing spam, retain fewer alterations from the primary image and eliminate multiplex replies to the near edge, it is one of the most well-known algorithms [24]. Second, Detecting iris boundaries using the circular Hough transform: the pupil/iris boundary is a strong edge whereas the iris/sclera boundary is a weak edge. The centers and radii of the two boundaries can then be calculated using the circular Hough transform using the edge image of an eye. Since the pupil is always within the iris region, the circular Hough transform for the iris/pupil boundary was carried out within the iris region rather than the entire eye region. This was done to first execute the Hough transform for the iris/sclera border [25]. Figure 3 illustrates the procedures for extracting the iris from an eye image. A circular Hough transform is used since the iris border in the edge image has more circular edges. Finding features that match the predetermined shape is the aim of the Hough transform, such lines and circles could be recognized using the Hough transform. The Hough transform can recognize the circles even if they are hazy and unfinished. Equation 2 shows, the circle's equation contains three variables (a, b and r), where r is the radius of the circle and the cycle values on the two axes are a and b [26].
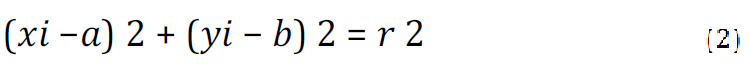
Every point in image is taken and rerendered on the space of the values of a and b to perform the circular Hough transform, this will result in the creation of a cycle in the Hough space. The point of which there are many cycles are intersected on indicating there is a cycle in the original image if the created cycles in the Hough images are intersected in a single point and by following the voting concept (i.e., more points meaning stronger evident to indicate there is a circle). The suggested method's procedures for locating the outer Iris border using the circular Hough transform are depicted in Figure 3 [27].
The image needs to be adjusted and placed into a similar gradient range after the iris has been segmented. It is required to normalize the iris image, so that it is represented with consistent measurements across all persons because the optical scale of the iris, the location of pupil inside the iris and the direction of the iris differ between people. The iris was unwrapped and transformed into its polar equivalent using the normalizing technique. Considering that the reference point in the eye image was the center of the pupil [28].
Iris Normalization
Eye images may vary in size due to the fact that they were captured from numerous subjects in varied settings. Therefore, to accomplish more precise iris identification, images should be standardized from diverse sizes into the same size. The iris region is changed into a rectangular zone to carry out this technique. For normalization, utilize Daugman's Rubber Sheet model. Equation 3 shows the rubber sheet, algorithm remains every pixel in the segmented iris region in the Cartesian (x,y) coordinates, to the polar coordinates (r,θ), where the interval of r is [0,1] and (θ) is at the [0,2π] angle, as presents in Figure 4 [29]:
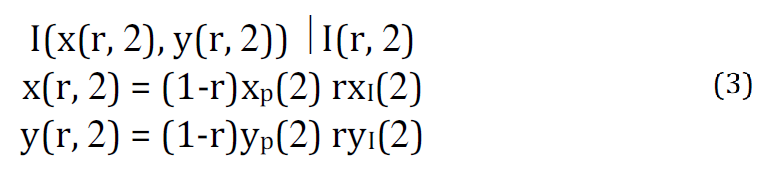
In which I(x, y) is the region of the iris, (x, y) is the main Cartesian coordinates, (r, θ) is the conformable polar coordinates Xp, Yp and X1, Y1 are the pupil and iris region coordinates along θ the direction [11].
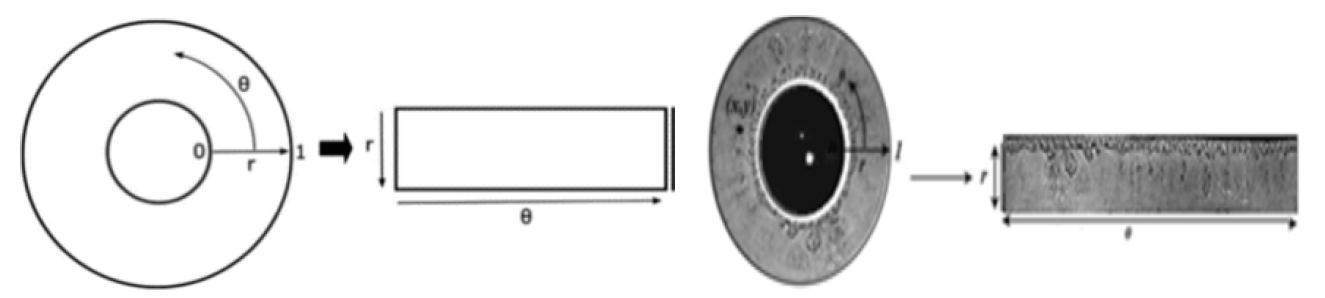
Figure 4: Daugman’s Rubber Sheet Algorithm [11]
Feature Extraction Using CNN
Convolutional neural network is a particular class of neural network approaches that has demonstrated superior performance to several traditional hand-crafted feature techniques in addition to being able to automatically train image feature representations. Neural network models rely on the computation of layers and have a hierarchical representation of their data. Because NN models are implemented sequentially, the output from one layer becomes the input for the subsequent layer. Every layer provides one representation level and each layer is parameterized by a set of weights. It should be emphasized that a set of biases as well as weights link the input units to the output units. Because the weights in CNN are shared locally, they are the same in all input locations. The weighted filter formed by similar output-related outputs [30].
Local receptive fields, weight sharing and down-sampling processes are the three elements that make up the CNN architecture as shown in Figure 5. Every neuron accepts input from a small piece of the layer above thanks to the local receptive field. The convolution filter is the same size as well [31].
Convolutional Neural Network formed with the help of different layers to perform the image classification task. The architecture of the CNN contains the different layers as follows.
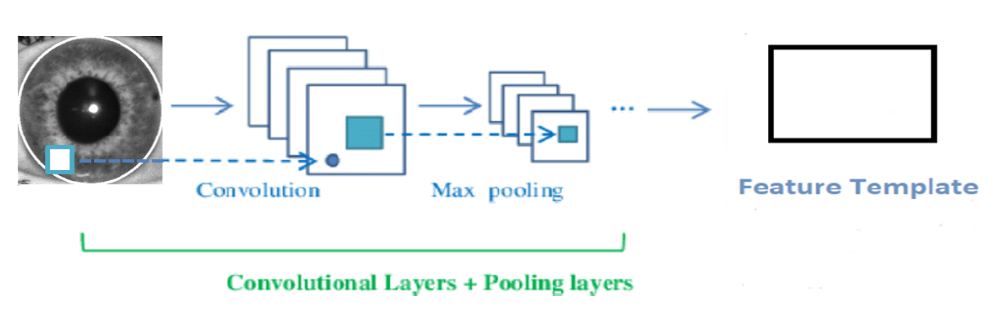
Figure 5: A Representation of the CNN Building [31]
Input Layer
This layer, receives raw images and then forwarded to following layers for features extraction [32].
The Convolutional Layer
Convolution layer is a framework with several fixed-size filters that enables the application of sophisticated functions to the input image. The locally trained filters are applied to the image to complete this procedure. Throughout the image during this procedure, each filter has the same weight and bias values. This is referred to as a weight sharing method and it allows for the representation of the same feature over the entire image. The region to which a neuron is connected at a lower layer is represented by its local receptive field. The size of the filters determines the size of the receptive field [33].
Let i represent the image, m*n and c*c be the size of both input image and kernel, while w and b are the weight and bias values of the filter. Calculate the output O0,0 using Equation 4, where f is the activation function. In this
process, the activation function can be either sigmoid or ReLu. Equation 5 illustrates the behavior of the ReLu activation function [34]:
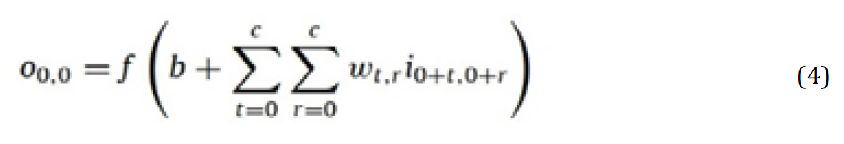
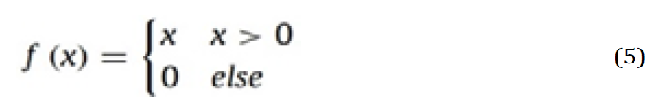
Activation Function
The essential purpose of activation function in each kind of neural network is to map the input to the output. The weighted summation of the neuron input and its bias (if present) is computed to obtain the input value. This means that by producing the corresponding output, the activation function decides whether or not to fire a neuron in response to a specific input. ReLU (Rectified Linear Unit) is the CNN context's most popular function. It changes the input's entire values to positive numbers. ReLU has an advantage over the others in that it requires less calculation [35].
The Pooling Layer
In addition to convolution layers, CNN also includes several pooling layers. After a convolutional layer, there can be a pooling layer right away. It implies that the network's pooling layers receive their inputs from the convolution layers' outputs. By using various functions to summarize subregions, like taking the average or maximum value, pooling operations reduce the size of the feature maps. The goal of pooling layers is to gradually lower the dimensionality of the data, which will also result in a decrease in the model's parameter count and procedural complexity, which will help to prevent overfitting. A number of the common pooling operations are max pooling, average pooling, spectral pooling, stochastic pooling, spatial pyramid pooling, L2-norm pooling and multiscale orderless pooling. The operation of max pooling are shows in Figure 6 [36].
The 'MAX' function is used by the pooling layer to scale the dimensionality of each activation map in the input. The activation map is scaled down to 25% of its original size in most CNNs while the depth volume is kept at its standard size. These are the available shapes of maxpooling layers with kernels of dimensionality of 2×2 applied with a stride of 2 on the spatial dimensions of the input. There are only two commonly used max-pooling techniques. The stride and filters of pooling layers are frequently both set to 2×2, allowing the layer to spread throughout the whole range of the input's spatial dimensions. Additionally, overlapping pooling is used, with a stride of 2 and a kernel size of 3×3. Having a kernel size greater than three, however, can occasionally cause the model's performance to decline noticeably due to the detrimental effects of pooling [37].
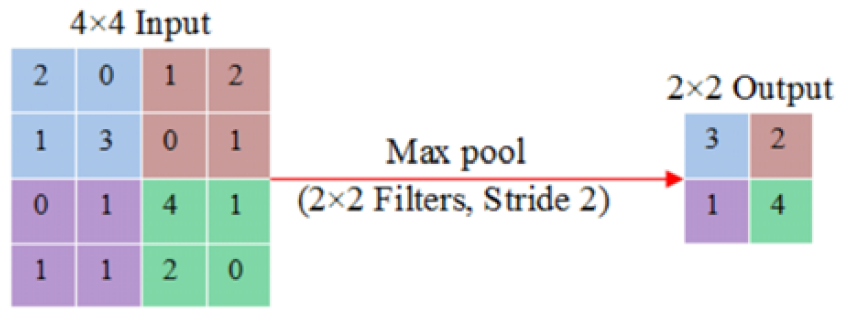
Figure 6: Max Pooling Operation [36]
Fully Connected Layer
The final convolution or pooling layer's output feature maps are typically flattened or converted into a one-dimensional (1D) array of numbers (or vector) and connected to one or more dense layers, also known as fully connected layers, in which each input and each output are connected by a learnable weight. A subset of fully connected layers then maps the features provided by the convolution layers and the downsampling layers to the network's final outputs, such as the probabilities for each class in classification tasks. The number of output nodes in the final fully connected layer normally equals the number of classes. Each fully connected layer is followed by a nonlinear function [38,39]. The output is forecasted into classes after passing through a fully connected layer (to classify the image) [40].
The aim of this work is recognizing the persons by eye iris using CNN to select the feature vector from iris images. The proposed architecture was developed using python. To measure the accuracy of the proposed approach, three dataset are used as present in Table 1. For each dataset, 50 person are used and for each person 10 images are selected, 5 images for left eye and 5 images for right one. For example, the AMF dataset which contains 540 images, was divided into 3 sets. The first set was used for training and contains 378 images. The second set was used for testing and contains 81 images and the third set was used for verification which contains 81 images also. In percentages, the training set consists of 70% of the augmented dataset, while the testing and verification phases each consist of 15%. Table 1 presents the accuracy gained from applying the proposed work on the selected dataset, where the results indicate higher accuracy especially in the third one.
Table 1: The Results of Applying the Proposed Method on Three Iris
Datasets
Dataset | Accuracy (%) |
CASIA-Iris-Interval (V4) | 97.02 |
IIT Delhi Iris Database | 97.96 |
AHMED MYASAR FATHI (AMF) iris dataset | 98.46 |
A promising area of security concern is iris recognition, which uses a person's iris to identify them. Calculating the iris characteristic makes it possible to identify every person in a population. Iris features cannot be lost or forgotten, they are difficult to reproduce, share or distribute and they require the individual to be present at the time of verification, which makes iris identification a desirable field. However, feature extraction and classification algorithms play a major role in the improvement of accuracy. This study emphasizes feature extraction and categorization as a result. CNN is a used as effective feature extraction and classification machine learning approach. The results of our experiments on three datasets to recognizing the person based on eye iris images have shown the good accuracy. This demonstrates that the suggested feature extraction and classification technique is effective at improving iris recognition accuracy.
Acknowledgment
The author’s thanks the "Department of Computer Science", "Collage of Science", "Mustansiriyah University", for supporting this work.
Ahmed, H.M. et al. “A Brief Survey on Modern Iris Feature Extraction Methods.” T. Journal, vol. 39, no. 1, 2021, pp. 123-129.
Nazmdeh, V. et al. “Iris Recognition: From Classic to Modern Approaches.” Proceedings of the IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), 2019, pp. 981-988.
Omran, M. and E.N. AlShemmary. “An Iris Recognition System Using Deep Convolutional Neural Network.” Journal of Physics: Conference Series, vol. 1530, no. 1, 2020, article 012159.
Dorgaleleh, S. et al. “Molecular and Biochemical Mechanisms of Human Iris Color: A Comprehensive Review.” Journal of Cellular Physiology, vol. 235, no. 12, 2020, pp. 8972-8982.
Janiesch, C. et al. “Machine Learning and Deep Learning.” Electronic Markets, vol. 31, no. 3, 2021, pp. 685-695.
Shaker, S.H. et al. “Identification Based on Iris Detection Technique.” International Journal of Information and Multimedia Technology, vol. 16, no. 24, 2022.
Li, Y.H. et al. “An Efficient and Robust Iris Segmentation Algorithm Using Deep Learning.” Mathematical Problems in Engineering, 2019.
Ahmadi, N. et al. “An Intelligent Method for Iris Recognition Using Supervised Machine Learning Techniques.” Optik, vol. 120, 2019, article 105701.
Chang, Y.T. et al. “Effectiveness Evaluation of Iris Segmentation by Using Geodesic Active Contour (GAC).” The Journal of Supercomputing, vol. 76, 2020, pp. 1628-1641.
Sardar, M. et al. “Iris Segmentation Using Interactive Deep Learning.” IEEE Access, vol. 8, 2020, pp. 219322-219330.
Therar, H.M. et al. “Multibiometric System for Iris Recognition Based Convolutional Neural Network and Transfer Learning.” IOP Conference Series: Materials Science and Engineering, vol. 1105, no. 1, 2021, article 012032.
Malgheet, J.R. et al. “Iris Recognition Development Techniques: A Comprehensive Review.” Computational Intelligence and Neuroscience, 2021, pp. 1-32.
Fathi, A.M. AMF Iris Dataset. Kaggle, April 2023, www.kaggle.com/datasets/ahmedmyasarfathi/amf-iris-dataset.
Kumar, S. et al. “Automated Detection of Eye Related Diseases Using Digital Image Processing.” Handbook of Medical Imaging Science and Applications, 2019, pp. 513-544.
Zhou, W. et al. “Research on Image Preprocessing Algorithm and Deep Learning of Iris Recognition.” Journal of Physics: Conference Series, vol. 1621, no. 1, 2020, article 012008.
Priyadharshini, P. et al. “Advances in Vision-Based Lane Detection Algorithm Based on Reliable Lane Markings.” Proceedings of the International Conference on Advanced Computing & Communication Systems (ICACCS), 2019, pp. 880-885.
Rachman, L. “Detection of Cholesterol Levels by Analyzing Iris Patterns Using Backpropagation Neural Network.” IOP Conference Series: Materials Science and Engineering, vol. 852, no. 1, 2020, article 012157.
Hassan, I.A. et al. “Enhance Iris Segmentation Method for Person Recognition Based on Image Processing Techniques.” TELKOMNIKA, vol. 21, no. 2, 2023, pp. 364-373.
Koç, O. et al. “Iris Recognition Performance Analysis for Noncooperative Conditions.” Proceedings of the International Conference on Computing, Electronics & Communications Engineering, 2020, pp. 172-175.
Sathiya, M. et al. “An Enhanced Ensemble Hybrid Deep Learning Algorithm for Improving the Accuracy in Iris Segmentation.” ICTACT Journal on Image and Video Processing, vol. 13, no. 3, 2023, pp. 2947-2952.
Jan, F. et al. “An Effective Iris Segmentation Scheme for Noisy Images.” Biomedical Engineering, vol. 40, no. 3, 2020, pp. 1064-1080.
Ridha, J.A. and J.H. Saud. “Iris Segmentation Approach Based on Adaptive Threshold Value and Circular Hough Transform.” Proceedings of the International Conference on Computer Science and Software Engineering (CSASE), 2020, pp. 32-37.
Bhuvaneswari, S. and P. Subashini. “Red-Channel Based Iris Segmentation for Pupil Detection.” Proceedings of the International Conference on Artificial Intelligence and Computer Vision, March 2023, pp. 231-241.
Sekehravani, E.A. et al. “Implementing Canny Edge Detection Algorithm for Noisy Image.” Bulletin of Electrical Engineering and Informatics, vol. 9, no. 4, 2020, pp. 1404-1410.
Garg, M. et al. “An Efficient Human Identification through Iris Recognition System.” Journal of Statistics and Probability Studies, vol. 93, 2021, pp. 701-708.
Omran, M. and E.N. AlShemmary. “Towards Accurate Pupil Detection Based on Morphology and Hough Transform.” Basrah Journal of Science, vol. 17, no. 2, 2020, pp. 583-590.
Mahameed, A.I. et al. “Iris Recognition Method Based on Segmentation.” Engineering Proceedings, 2022, pp. 166-176.
Salih, B.M. et al. “Gender Classification Based on Iris Recognition Using Artificial Neural Networks.” Qalaai Zanist Journal, vol. 1, no. 2, 2021, pp. 156-163.
Rafik, H.D. and M. Boubaker. “Application of Metaheuristic for Optimization of Iris Image Segmentation.” Proceedings of the International Conference on Communications, Control Systems and Signal Processing, 2020, pp. 142-150.
Kattenborn, T. et al. “Review on Convolutional Neural Networks (CNN) in Vegetation Remote Sensing.” International Journal of Applied Earth Observation and Geoinformation, vol. 173, 2021, pp. 24-49.
Azam, M.S. and H.K. Rana. “Iris Recognition Using Convolutional Neural Network.” International Journal of Computer Applications, vol. 175, no. 12, 2020, pp. 24-28.
Krishna, S.T. and H.K. Kalluri. “Deep Learning and Transfer Learning Approaches for Image Classification.” International Journal of Recent Technology and Engineering, vol. 7, no. 5S4, 2019, pp. 427-432.
Saddam, E.N. et al. “Patient’s Pain Recognition by Using Deep Models Based on Transfer Learning.” Proceedings of the International Conference on Data Science and Intelligent Computing, 2022, pp. 129-134.
Sarıgül, M. et al. “Differential Convolutional Neural Network.” Neural Networks, vol. 116, 2019, pp. 279-287.
Bhatt, D. et al. “CNN Variants for Computer Vision: History, Architecture, Application, Challenges and Future Scope.” Electronics, vol. 10, no. 20, 2021.
Sakib, S. et al. “An Overview of Convolutional Neural Network: Its Architecture and Applications.” 2019. https://doi.org/10.20944/preprints201811.0546.v4.
Akhtar, N. et al. “Interpretation of Intelligence in CNN-Pooling Processes: A Methodological Survey.” Neural Computing and Applications, vol. 32, no. 3, 2020, pp. 879-898.
Yamashita, R. et al. “Convolutional Neural Networks: An Overview and Application in Radiology.” Insights into Imaging, vol. 9, 2018, pp. 611-629.
Sejuti, Z.A. and M.S. Islam. “An Efficient Method to Classify Brain Tumor Using CNN and SVM.” Proceedings of the International Conference on Robotics, Electrical and Signal Processing Techniques, 2021, pp. 644-648.
Desai, M. and M. Shah. “An Anatomization on Breast Cancer Detection and Diagnosis Employing MLP and CNN.” Computational Engineering, vol. 4, 2021, pp. 1-11.
