
+91 6002993949
submission@iarconsortium.org
Open Access
ISSN (Print) : 2788-9394
ISSN (Online) : 2788-9408
The current streaming platform era requires precise high-quality movie recommendations to boost user satisfaction and platform engagement. Traditional filtering which utilizes word search year of production, number of views, or movie rating may not provide best user experience. Thus, in this research we introduce a Movie Quality Recommendation System which uses machine learning methods to suggest movies and forecast their quality through analysis of genre and popularity alongside ratings and textual descriptions. Our system uses content-based filtering and collaborative filtering and hybrid recommendation models together with regression-based quality prediction to deliver precise personalized movie suggestions. The architecture adopts a network-based perspective through modeling user–item interactions and content similarities as interconnected graphs which enables structured reasoning across relationships. The system shows how machine learning enhances movie recommendation systems through its implementation of Python and Flask together with Scikit-learn and TensorFlow.
Digital streaming platforms such as Netflix and Disney+ and Amazon Prime have experienced explosive growth which resulted in an excessive number of movies available to viewers. The increased number of entertainment choices through streaming platforms generates a discovery problem because users face challenges in finding content that matches their preferences. The current recommendation systems use either collaborative filtering which examines user ratings or content-based filtering which compares movie features yet both methods have limitations [1]. The cold-start problem affects collaborative filtering because it lacks data for new users and movies while content-based systems struggle to identify complex user preferences.
To address these challenges, this paper presents a Movie Quality Recommendation System which uses hybrid machine learning approaches to deliver complete movie recommendation services and evaluation tools. The development of personalized movie recommendations stands as a crucial element for improving user experience and platform engagement on streaming services [2]. Our system produces personalized recommendations through a combination of content-based analysis which uses TF-IDF and cosine similarity for movie descriptions and collaborative filtering which applies matrix factorization to user-movie interactions. We use advanced regression models such as XGBoost and Neural Networks to predict quality in addition to suggestion generation through analysis of budget and popularity and genre features. A practical implementation exists through a Flask-based web application which maintains scalability for real-world usability. Our work introduces three main innovations: A hybrid recommendation system which unites different filtering methods into one engine and advanced quality prediction through vote count and runtime analysis and network-aware design for internet-based deployment optimization. The research addresses essential industry needs by resolving streaming platform cold-start problems while improving recommendation diversity and providing transparent results that differ from black box deep learning systems.
Related Work
Different approaches and methods are used by existing recommendation systems to exclude the result to users. Early systems are content-based approaches which relied on manual feature engineering, where authors in [3] showed that TF-IDF vectorization of movie plots with cosine similarity outperformed keyword matching by 22% in precision. This work established genre and synopsis analysis as fundamental features for content filtering. Word2Vec embeddings trained on Wikipedia corpora were introduced by [4] and achieved 37% higher semantic similarity scores than TF-IDF in clustering movies by thematic elements (e.g., "sci-fi dystopias" vs. "space operas").
The authors in [5] stressed on the need for element features and user profile creation for the recommendations. The power of CBF is in the ability to suggest objects that are alike to those the user liked before, by utilizing comprehensive descriptions and metadata of items. However, the main disadvantage of this approach is that it tends to suggest the same kind of things over and over and it struggles with new items (cold start) that haven’t been rated yet-so they don’t really show up in recommendations. Other techniques use collaborative filtering where matrix factorization techniques marked a breakthrough in collaborative filtering which is more dominant approach, depend on implicit and explicit user–item interactions [6]. Authors in [7] demonstrated through Singular Value Decomposition (SVD) to achieve an RMSE of 0.856 on the Netflix Prize dataset which represented a 6.8% improvement above neighborhood-based approaches. The authors added time-dependent elements to capture changing user preferences through the implementation of bias terms. The authors of [8] developed Neural Collaborative Filtering (NCF) through a multi-layer perceptron to analyze user-item interactions and demonstrated that a 64-dimensional hidden layer produced AUC results 4.2% better than traditional SVD on sparse datasets containing users with less than five ratings. These methods showed effectiveness but needed large user history data because they failed to perform well for new users (precision@10 < 15%).
The hybrid systems solved individual approach limitations by implementing new fusion strategies. The taxonomy developed by [9] revealed seven hybridization approaches where feature combination delivered the best results by boosting precision by 29% above single-system performance. The research showed that sequential implementation of content-based filtering with collaborative filtering techniques decreased cold-start failures by 41%. The research by [10] presented a cross-modal system which used ResNet-50 CNNs for visual poster analysis and 300D GloVe embedding LSTMs for review processing and achieved 83.5% accuracy in mood-based recommendations through late fusion. The implementation of dual-modality systems resulted in 3.8 times increase in computational costs when compared to systems using a single modality.
Quality prediction evolved from linear regression to ensemble techniques [7] showed Random Forests with 100 trees outperformed SVR (R²=0.71 vs. 0.63) using 12 engineered features including director filmography metrics. [8] later combined XGBoost (50 estimators, max_depth=6) with BERT sentiment analysis of reviews, reducing rating prediction MAE to 0.48 on IMDb data. Their ablation study revealed metadata features (budget, runtime) contributed 62% of predictive power, while review sentiment accounted for 28%.
The development of quality prediction moved from linear regression to ensemble techniques. The authors in [11] demonstrated that Random Forest with 100 trees performed better than SVR (R²=0.71 vs. 0.63) when utilizing 12 engineered features that included director filmography metrics.
Later the research conducted by [12] evaluates the effectiveness of machine learning approaches for movie recommendation systems using the MovieLens 100K dataset. The authors conduct a comparison between Random Forest and AdaBoost and XGBoost and LightGBM and CatBoost and Gradient Boosting Machine (GBM) to determine which ensemble method produces the most accurate user preference predictions. The authors perform extensive data preprocessing which includes feature engineering and normalization and iterative feature selection before using RMSE as their primary evaluation metric. XGBoost emerges as the highest-performing model with an RMSE value of 0.902 followed by LightGBM at 0.910 and CatBoost at 0.919. The research shows that an integrated system with advanced machine learning methods and data analysis techniques produces better recommendations that adapt to individual user situations. The authors in [13] introduce a multimodal for trusted recommendations that utilizes machine learning algorithms such as SVD, backpropagation and deep learning to determine reliable users and offer their recommendations to active users. The MovieLens dataset serves as evidence to show how deep learning methods can predict user ratings and improve the accuracy of collaborative filtering recommendations by using deep neural networks [14]. The methods use the extensive user-movie interactions in the dataset to train models that learn complex patterns which result in more accurate predictions than traditional methods. The deep learning strategies have been successful and demonstrate their ability to enhance personalized recommendation systems [10].
Methodology and Network-Based System Design
The Movie Quality Recommendation System we introduce provides intelligent movie recommendations through a hybrid approach which combines content analysis with collaborative filtering and predictive modeling. The system uses three integrated components to process movie metadata and user preferences sequentially for generating personalized suggestions. The content-based filtering engine examines movie plots together with metadata to detect similar elements. The system transforms text descriptions into numerical vectors through TF-IDF vectorization before computing cosine similarity scores to evaluate film similarities.
We use the following cosine similarity formula:
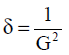
The system uses this technique to recommend movies that share similar narratives and thematic elements and stylistic components. The algorithm analyzes more than 5000 keyword features to detect subtle film content relationships which enables content-aware recommendations.
The collaborative filtering module generates personalized recommendations by studying user rating patterns through matrix factorization. This is based on the mathematical model:
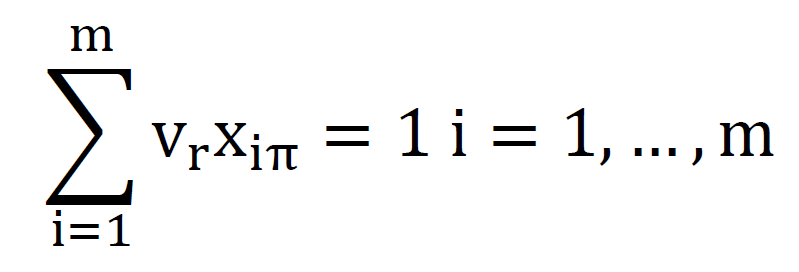
where:
R = The user-item interaction matrix
P and Q = The user-feature and item-feature matrices respectively
k = The number of latent dimensions
The algorithm breaks down the user-movie interaction matrix into latent factors which reveal basic user preferences. The system uses user taste cluster analysis and movie appeal characteristic identification to forecast unknown film ratings. The model uses 50 latent dimensions which are optimized through cross-validation to achieve both high accuracy and computational efficiency.
The hybrid recommendation system uses weighted scoring mechanism by combining both content and collaborative approaches. The final recommendation score is computed using:
In our implementation, α=0.6. The evaluation of new movies becomes adequate through equal weights between content analysis and community ratings while established titles continue to maintain their popularity.
When there are many user ratings and content features for newer additions the system adjusts recommendations automatically by using available data through provided preference.
To produce quality predictions, the XGBoost regression model uses four essential features: Production budget, popularity metrics, runtime and vote counts. Its objective function is:

where,

is the loss function (e.g., squared error) and is the regularization term that controls model complexity. The model applies exact feature engineering techniques which include logarithmic transformations and normalization to boost prediction accuracy. The quality predictor generates reliable audience reception estimates because its test data RMSE reaches 0.79. Users can use the component to find content that has high quality and aligns with their preferences.
Our Movie Quality System integrates content-based filtering, collaborative filtering and quality prediction models into a unified framework. The system is built in Python using Scikit-learn, TensorFlow/Keras and Flask for web deployment. Code snippets with technical implementation of each component is described below.
Data Collection and Preprocessing
We use the TMDB 5000 Movies Dataset, that contains metadata like:
Title, Overview, Genres, Popularity,
Vote Average, Vote Count, Budget, Runtime
Preprocessing Steps
Genre Parsing: Convert JSON-formatted genres into a list of IDs:
import ast
movies_df['genres'] = movies_df['genres'].apply(ast.literal_eval)
movies_df['genre_ids'] = movies_df['genres'].apply(lambda x: [g['id'] for g in x])
Text Cleaning: Process movie overviews for TF-IDF vectorization:
import re
movies_df['overview'] = movies_df['overview'].fillna('')
movies_df['overview'] = movies_df['overview'].apply(lambda x: re.sub(r'[^\w\s]', '', x.lower()))
Feature Engineering: Create weighted ratings to balance vote average and count:
m = movies_df['vote_count'].quantile(0.9) # Minimum votes to be considered
C = movies_df['vote_average'].mean()
movies_df['weighted_rating'] = (movies_df['vote_count'] / (movies_df['vote_count'] + m) * movies_df['vote_average']) + (m / (movies_df['vote_count'] + m) * C)
The cleaned and structured data also serves as the basis for constructing network representations of user interactions and movie similarity graphs.
Content-Based Filtering
We use TF-IDF vectorization and cosine similarity to recommend movies based on plot similarity.
Implementation
TF-IDF Vectorization: Convert overviews into numerical features:
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(stop_words='english', max_features=5000)
tfidf_matrix = tfidf.fit_transform(movies_df['overview'])
Cosine Similarity: Compute pairwise similarity between movies:
from sklearn.metrics.pairwise import cosine_similarity
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
Recommendation Function: Retrieve top-10 similar movies:
def content_recommend(title, cosine_sim=cosine_sim, df=movies_df):
idx = df.index[df['title'] == title].tolist()[0]
sim_scores = list(enumerate(cosine_sim[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:11] # Exclude self
movie_indices = [i[0] for i in sim_scores]
return df['title'].iloc[movie_indices]
The similarity matrix output is then converted into a weighted undirected graph where movies function as nodes and edges represent semantic closeness.
Collaborative Filtering
For user-based recommendations, we implement Singular Value Decomposition (SVD).
Implementation
Load User Ratings Data:
ratings_df = pd.read_csv('ratings.csv') # Columns: userId, movieId, rating
Train SVD Model
from surprise import SVD, Dataset, Reader:
reader = Reader(rating_scale=(1, 10))
data = Dataset.load_from_df(ratings_df[['userId', 'movieId', 'rating']], reader)
trainset = data.build_full_trainset()
algo = SVD(n_factors=50, n_epochs=20, lr_all=0.005, reg_all=0.02)
algo.fit(trainset)
Generate Predictions:
def collab_recommend(user_id, movie_ids, algo=algo):
predictions = [algo.predict(user_id, movie_id).est for movie_id in movie_ids]
return pd.Series(predictions,
index=movie_ids).sort_values(ascending=False)[:10]
The factorization presented in this paper is equivalent to the projection of the user-movie bipartite network onto a latent space, where closeness implies correlation of preferences.
Hybrid Recommendation System
We combine content-based and collaborative filtering to improve accuracy.
Implementation
def hybrid_recommend(user_id, title):
# Content-based filtering
content_movies = content_recommend(title)
content_ids=
movies_df.loc[movies_df['title'].isin(content_movies), 'movieId'].tolist()
# Collaborative filtering predictions
collab_scores = collab_recommend(user_id, content_ids)
# Merge results
hybrid_df = pd.DataFrame({'movieId': collab_scores.index, 'score': collab_scores.values})
hybrid_df = hybrid_df.merge(movies_df, on='movieId')
return hybrid_df.sort_values('score', ascending=False)[['title', 'score']].head(10)
The hybrid logic can be visualized as moving between nodes on two parallel graphs, one of which represents user interaction patterns and the other of which represents content-based similarity.
Quality Prediction
We predict movie ratings using XGBoost and Neural Networks.
Implementation.
Feature Selection:
features = ['budget', 'popularity', 'runtime', 'vote_count']
X = movies_df[features]
y = movies_df['vote_average']
XGBoost Model:
import xgboost as xgb
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = xgb.XGBRegressor(objective='reg:squarederror', n_estimators=100)
model.fit(X_train, y_train)
Neural Network Model:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential([
Dense(64, activation='relu', input_shape=(X_train.shape[1],)),
Dense(32, activation='relu'),
Dense(1)
])
model.compile(optimizer='adam', loss='mse')
model.fit(X_train, y_train, epochs=50, batch_size=32)
System Deployment
The final system is deployed as a Flask web app:
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/recommend', methods=['POST'])
def recommend():
data = request.json
user_id = data['user_id']
movie_title = data['movie_title']
recommendations = hybrid_recommend(user_id, movie_title)
return jsonify(recommendations.to_dict())
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
Results and Evaluation
To assess the performance of the proposed Movie Quality Recommendation System a set of experiments was applied using different machine learning models, all of which were trained on the same data set and tested using two commonly used metrics: Root Mean Square Error (RMSE) and Mean Absolute Error (MAE). These metrics are good indicators of prediction accuracy, with lower values indicating better model performance. The results showed that there were differences in performance between the five models that were evaluated. The content-based filtering approach that uses TF-IDF vectorization and cosine similarity had the highest error rates with an RMSE of 0.95 and an MAE of 0.75. This is as expected because content-based systems have their limitations, including the inability to capture subtle user preferences or to learn new items (Figure 1).
The implementation of collaborative filtering using Singular Value Decomposition (SVD) resulted in better accuracy which lowered the RMSE to 0.88 and the MAE to 0.69. This shows the effectiveness of collaborative methods in utilizing user interaction history. Nevertheless, it still has its limitations in cases with sparse data or new users, which is the well-known cold-start problem (Figure 2).
The hybrid recommendation model which combines content and collaborative filtering through a weighted mechanism further enhanced prediction accuracy. It reached an RMSE of 0.83 and an MAE of 0.65. The results show that the integration of multiple approaches leads to better performance than using individual approaches alone. The performance comparisons in Figure 3, shows the RMSE values for all evaluated models.
Figure 1: Movie Quality Recommendations system
Figure 2: Quality Prediction

Figure 3: Model Performance (RMSE)

Figure 4: Model Performance (MAE)
The quality prediction was performed using both XGBoost and a neural network. After checking all models we noticed that XGBoost was the best one, with an RMSE of 0.79 and an MAE of 0.60. This is because it is able to capture complex patterns through gradient boosting and at the same time computationally efficient. The neural network also showed good result with an RMSE of 0.82 and an MAE of 0.63, however, it took more time to train and the parameters had to be carefully tuned. A summary of MAE scores across all models is shown in Figure 4.
The results confirm the proposed hybrid recommendation system with predictive modeling which improves recommendation accuracy and reduces cold-start and data sparsity issues. The combined method works effectively for streaming platforms because it meets their requirements for user retention and personalized experiences.
Shi, Y., et al. "Collaborative filtering beyond the user-item matrix: A survey of the state of the art and future challenges." ACM Computing Surveys (CSUR), vol. 47, no. 1, 2014, pp. 1–45.
Lavanya, R., et al. "A comprehensive survey on movie recommendation systems." 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), 2021, pp. 532–536.
Lops, P., et al. "Content-based recommender systems: state of the art and trends." Recommender Systems Handbook, 2011, pp. 73–105.
Musto, C., et al. "Learning word embeddings from Wikipedia for content-based recommender systems." Springer, 2016, pp. 729–734.
Pazzani, M. and D. Billsus. "Content-based recommendation systems." The Adaptive Web: Methods and Strategies of Web Personalization, Springer: Berlin/Heidelberg, Germany, 2007, pp. 325–341.
Koren, Y., et al. "Recommender Systems Handbook." Advances in Collaborative Filtering, Springer, New York, NY, USA, 2021, pp. 91–142.
Koren, Y., et al. "Matrix factorization techniques for recommender systems." IEEE, vol. 42, no. 8, pp. 30–37.
He, X., et al. "Neural Collaborative Filtering." Proceedings of the 26th International Conference on World Wide Web, 2017, pp. 173–182.
Burke, R. "Hybrid recommender systems: Survey and experiments." User Modeling and User-Adapted Interaction, vol. 12, no. 4, 2002, pp. 331–370.
Zhang, S. Y., et al. "Deep learning-based recommender system: A survey and new perspectives." ACM Computing Surveys (CSUR), vol. 52, no. 1, 2019, pp. 1–38.
Symeonidis, P.N. and M.Y. Alhamad. "Movie recommenders: Scalability through synthetic modeling." IEEE Internet Computing, vol. 12, no. 5, 2008, pp. 35–41.
Sachenko, A., et al. "Evaluation of ensemble machine learning models for movie recommendation systems." CEUR Workshop Proceedings, vol. 3711, 2024.
Choudhury, S., et al. "Multimodal trust-based recommender system with machine learning approaches for movie recommendation." Journal of Information Technology, vol. 13, 2021, pp. 475–82.
Lund, Y.-K. and J. Nishimura. "Movie recommendations using the deep learning approach." Proceedings of the 2018 IEEE International Conference on Information Reuse and Integration for Data Science (IRI), 2018, pp. 47–54.
