
+91 6002993949
submission@iarconsortium.org
Open Access
ISSN (Print) : 2708-5155
ISSN (Online) : 2708-5163
Network slicing is a key technology to support a range of services with diverse Quality of Service (QoS) requirements in 5G networks and the upcoming 6G networks. However, dynamic resource allocation to network slices presents a challenge due to dynamic traffic pattern and strict latency requirements. In this paper, we propose an intelligent network slicing optimization approach based on Deep Reinforcement Learning (DRL) to address these challenges. Our approach facilitates online decision-making by learning network resource allocation policies over time in response to changing traffic demands, priority and latency constraints. The DRL strategy is dynamic and allocates resources to maximise network performance while adhering to Service Level Agreement (SLA) requirements, as opposed to the static and rule-based resource allocation approaches. Our simulations have shown that the proposed model has improved resource efficiency, end-to-end delay and QoS satisfaction compared to traditional resource allocation strategies. Our findings demonstrate the advantages of using artificial intelligence for future network management, which enables scalable, adaptable and efficient 5G/6G networks.
The rise of wireless communication technologies has revolutionised the current digital landscape with the roll-out of fifth-generation (5G) networks and advancement in sixth-generation (6G) communication systems [1,2]. Future networks are expected to support a range of different services including enhanced Mobile Broadband (eMBB), Ultra-Reliable Low-Latency Communications (URLLC) and massive Machine-Type Communications (mMTC) [3].
These services have diverse and even conflicting Quality of Service (QoS) demands, such as latency, data rate, reliability and density. This means existing network designs are unable to meet this demand for diversity and variability. Network slicing is an important technology that allows multiple virtual networks to be run on top of a common physical network infrastructure. Network slices can then be tailored to the requirements of different services or applications to enhance customisation and flexibility. But network slicing raises issues of resource allocation and management, particularly dynamic allocation and optimisation among slices. The variability of demand, low-latency demands and resource scarcity pose challenges in managing the network slices [4,5].
Conventional resource allocation approaches, such as static allocation and heuristic-based allocation, are not sufficient to deal with the dynamic and stochastic nature of today's network environments. These methods are not adaptive and do not respond to changes in network environments, leading to poor network performance and resource under-utilisation. By contrast, intelligent optimization techniques based on Artificial Intelligence (AI), such as Deep Reinforcement Learning (DRL), show a lot of potential for self-adaptive network management. DRL combines the learning ability of reinforcement learning with the feature representation capability of the deep neural network to allow agents to learn policies from their interactions with complex environments. For network slicing, DRL can learn to adjust resource allocation policies to the network state, such as traffic load, latency requirements and priority of network slices. This enables the system to learn and adaptively improve its performance without violating the Service-Level Agreement (SLA) [6,7].
To address these issues, we propose a Deep Reinforcement Learning (DRL) empowered intelligent network slicing approach in this paper. Our approach models resource allocation as a Markov Decision Process (MDP), where the learning agent receives rewards when interacting with the network environment. The framework offers flexible, scalable and efficient resource allocation in dynamic 5G/6G networks using advanced DRL algorithms. In this paper, we make the following contributions:
Design a DRL solution for dynamic and adaptive slicing
Modeling the problem of resource allocation as an MDP for dynamic networks
Optimizing the QoS by maximizing latency, throughput and fairness
Simulations to evaluate the performance of proposed solution compared to traditional methods
This paper is structured as follows. Section 2 discusses the existing literature on network slicing and smart resource allocation. Section 3 describes the system model and problem. Section 4 outlines the proposed DRL-based optimization approach. Section 5 outlines the simulation settings and results. Finally, Section 6 concludes the paper and proposes future work.
Related Works
Network slicing is now a key enabling technology to 5G and beyond networks since it can enable multiple virtual networks to utilize a common physical infrastructure and meet various QoS needs [8-10]. In recent years, intelligent resource allocation, particularly when based on Deep Reinforcement Learning (DRL), has become the subject of more and more studies thanks to its dynamic flexibility to traffic, mobility and heterogeneous service needs. For example, Cai et al. [11] suggested a network slicing online resource allocation methodology using DRL and demonstrated that learning-based allocation could enhance the use of resources and meet different QoS criteria in RAN slicing. In their study, Malta et al. [12] created a DRL framework to 5G network slicing in eMBB, URLLC and mMTC scenarios, where the
agent selected access scheme dynamically, including OMA, NOMA and RSMA, to optimize sum rate and decoding performance of devices. Azimi et al. [13] proposed a federated DRL model of 5G-RAN slicing that is mobility-aware and energy-efficient. Their approach integrates federated advantage actor-critic learning and deep learning prediction to distribute power and radio resources taking into account mobility, inter-RAN interference, slice isolation and energy efficiency. Other more recent papers have generalized network slicing optimization toenergy-aware environments and 6G-oriented environments. Wang et al. [14] suggested a DRL-based energy-aware slice deployment policy that maximizes the energy usage and deployment capacity. Recent surveys also highlight that DRL will become an important method to autonomous 6G AI-RAN slicing, yet issues of transparency, scalability, generalization and explainability are still a problem [15,16].
Nevertheless, despite all these advances, most of the existing solutions are aimed at one objective, which could be throughput maximization, energy efficiency or slice admission control. Moreover, some of the models are characterized by excessive computational complexity, lack of adaptability to fast changing traffic conditions or lack of fairness between slices. Accordingly, the paper suggests a DRL-based network slicing optimization framework to collectively optimize throughput, latency, packet loss, spectral efficiency and fairness to facilitate adaptive and QoS-aware resource allocation in 5G/6G networks.
In this section, we provide the proposed Deep Reinforcement Learning (DRL)-based intelligent network slicing optimization framework. The approach comprises of three parts: modeling, MDP formulation and design of the DRL-based algorithm. This section describes the proposed DRL-based network slicing optimization framework, the system model, MDP formulation and learning process (Figure 1).
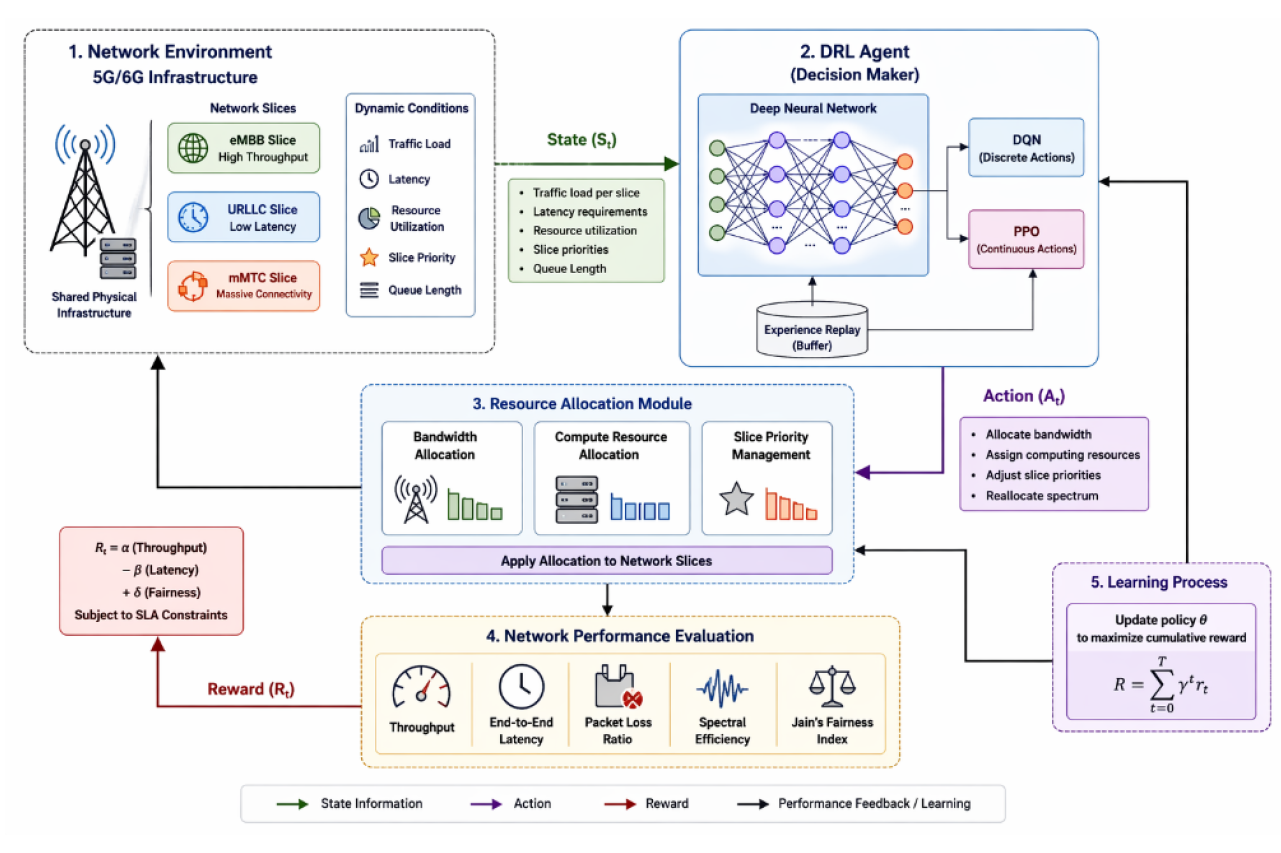
Figure 1: DRL-Based Intelligent Network Slicing Optimization Framework
System Model
The network scenario involves a 5G/6G infrastructure to support multiple network slices, which are associated with different types of services, such as enhanced Mobile Broadband (eMBB), Ultra-Reliable Low-Latency Communications (URLLC) and massive Machine-Type Communications (mMTC). The slices share a set of physical resources, such as bandwidth, spectrum and computing resources. Let the system include N network slices, where each slice i∈{1,2,…,N} considered by:
Traffic demand Di(t)
Latency requirement Li
Priority weight Wi
Allocated resources Ri(t)
The goal is to efficiently assign resources between slices dynamically in order to maximize network efficiency, without violating QoS constraints.
Problem Formulation
The network slicing optimization problem is modeled as a sequence decision-making process, i.e., the system should continuously adjust the allocation of resources to the change in network conditions.
Objective Function
The objective is to maximise the long run cumulative reward which is a measure of the overall network performance:
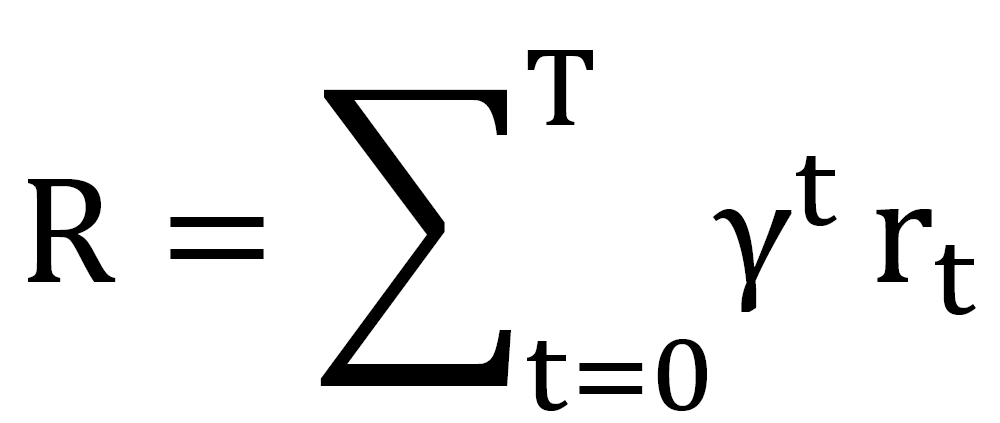
Where, rt denotes the immediate reward at time t and γ∈[0,1] is the discount factor.
Reward Design
The reward functional is well formulated to balance various performance measures:
Throughput maximization
Latency minimization
Fairness among slices
An average formulation of a reward is:
rt=α⋅Throughput−β⋅Delay+δ⋅Fairness
where α,β,δ are weighting factors.
Markov Decision Process (MDP) Formulation
The issue is formulated as Markov Decision Process with the following definition (S,A,P,R,γ):
State Space (S)
The existing state of the network is:
Traffic load per slice
Queue length
Resource utilization
Latency status
St={Di(t),Ri(t),Qi(t),Li}
Action Space (A)
The agent makes decisions on how to spend resources:
Adjust bandwidth allocation
Reassign computational resources
Modify slice priorities
At={R1(t),R2(t),…,RN(t)}
State Transition (P)
The network is dynamically updated depending on the changes in traffic and past activities.
Reward Function (R)
Gives feedback on system performance following each action.
Proposed DRL Framework
A Deep Reinforcement Learning framework is used to solve the MDP. The suggested system incorporates:
Deep Q-Network (DQN)
Feasible in discrete action spaces
Approximates Q-values with neural networks
Q(s,a)=Q(s,a;θ)
Proximal Policy Optimization (PPO)
Deals with continuous action spaces
Gives consistent and effective policy updates
Learning Process
The DRA agent operates with the environment in the following manner:
Observe current state St
Select action At using policy π
Execute action and observe reward rt
Revise policy based on experience gained
Fairness Constraint
In order to distribute the resources fairly among slices, the Fairness Index introduced by Jain is implemented:
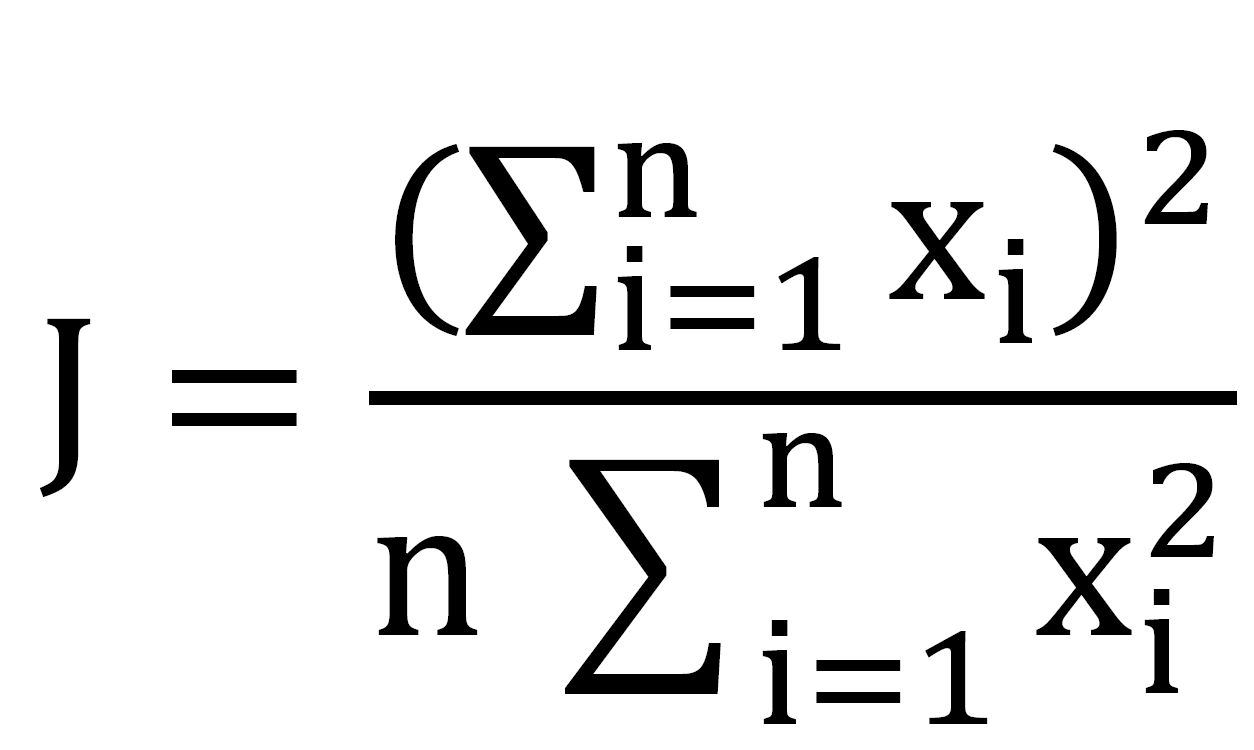
where, Xi represents the throughput of slice i.
Simulation Setup and Experimental Design
This section outlines the simulation environment, performance metrics and experimentation setup used to evaluate the performance of the proposed Deep Reinforcement Learning (DRL)-based network slicing optimization framework.
Simulation Environment
The effectiveness of the proposed framework is assessed through simulation to create a dynamic 5G/6G network environment with multiple service slices. The simulator is developed using Python programming and deep learning frameworks (PyTorch/TensorFlow) for DRL model training and testing. Three key slices are considered in the network:
eMBB (enhanced Mobile Broadband): High rate services
URLLC (Ultra-Reliable Low-Latency Communications): Ultra low latency services
mMTC (massive Machine-Type Communications): Large scale IoT
The slices compete with each other for network resources (bandwidth and computing). The network is assumed to be in dynamic traffic conditions with variable user requests and network conditions. The simulation parameters are carefully adjusted to match the realistic 5G/6G network scenarios (such as varying user density, traffic loads and resource limitations) for the proposed framework to be tested for performance as shown in Table 1.
Table 1: Simulation Parameters
Parameter | Value |
Number of Slices | 3 (eMBB, URLLC, mMTC) |
Number of Users | 50-200 |
Total Bandwidth | 100 MHz |
Time Slots | 1000 |
DRL Episodes | 1000-2000 |
Learning Rate | 0.001 |
Discount Factor (γ) | 0.9 |
Replay Buffer Size | 10,000 |
Batch Size | 64 |
Experimental Design
The simulations will explore the adaptability and performance of the proposed DRL-based resource allocation strategy under various network scenarios.
Baseline Methods for Comparison
The effectiveness of the proposed approach is compared to, to validate it:
Static Allocation: Static allocation of resources
Round-Robin Allocation: Shares resources equally
Priority-based allocation: Heuristic-Based Allocation
Evaluation Scenarios
The following are the scenarios that will be thought of:
Low Traffic Load: Static network conditions
Moderate Traffic Load: Equilibrium resource demand
High Traffic Load Congestion of network conditions
Dynamic Traffic Variation: Static changes in the user demand
Training Strategy
DRA agent is trained by the ongoing interaction with the network environment:
Exploration-exploitation balance with ε-greedy strategy
To stabilize learning, experience replay
Convergence periodic policy updates
Performance Metrics
Several Quality of Service (QoS) and performance indicators are used to fully assess the proposed framework.
Throughput
Throughput is a measure of the amount of data sent successfully over all slices:
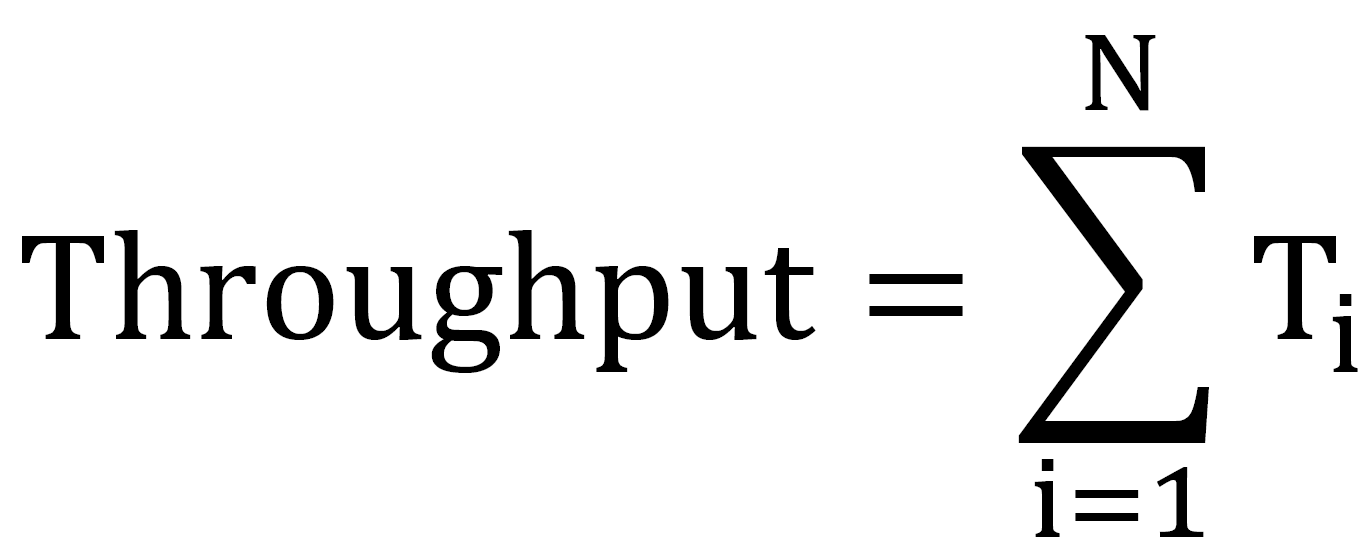
where, Ti is the throughput of slice i.
End-to-End Delay
This measure is used to measure the latency of data packets:
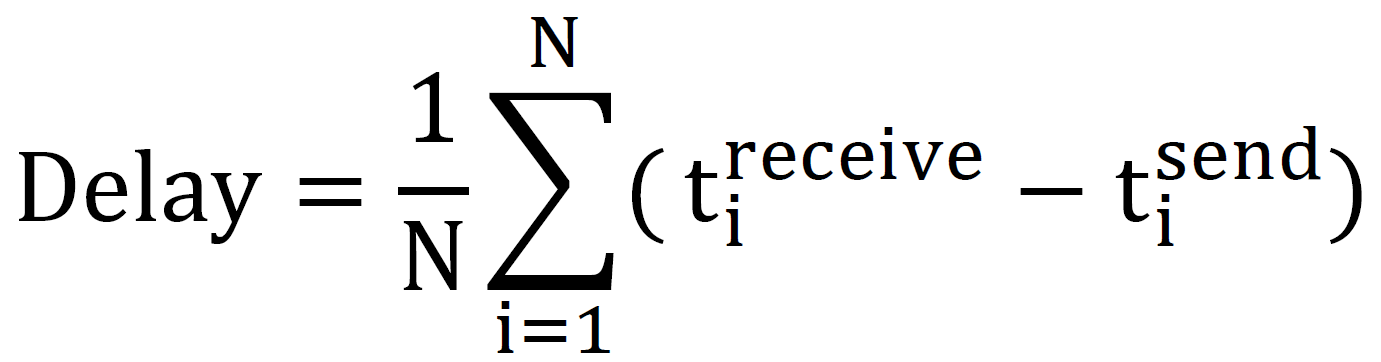
Packet Loss Ratio (PLR)
PLR is a measure of the network reliability:

Spectral Efficiency
Measures the efficiency with which the spectrum is used:
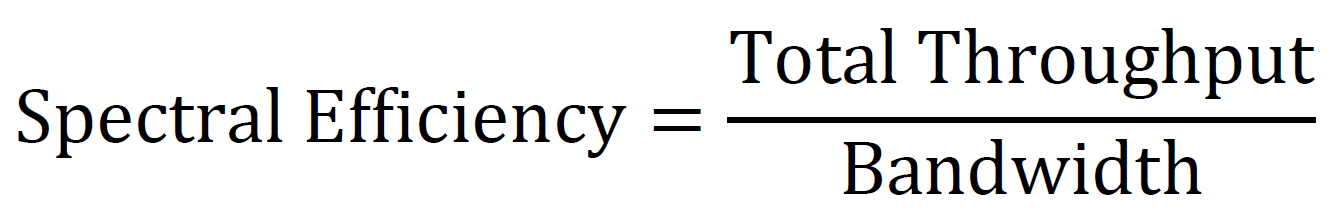
Fairness Index
In order to assess the fairness across slices, the Fairness Index by Jain is applied:
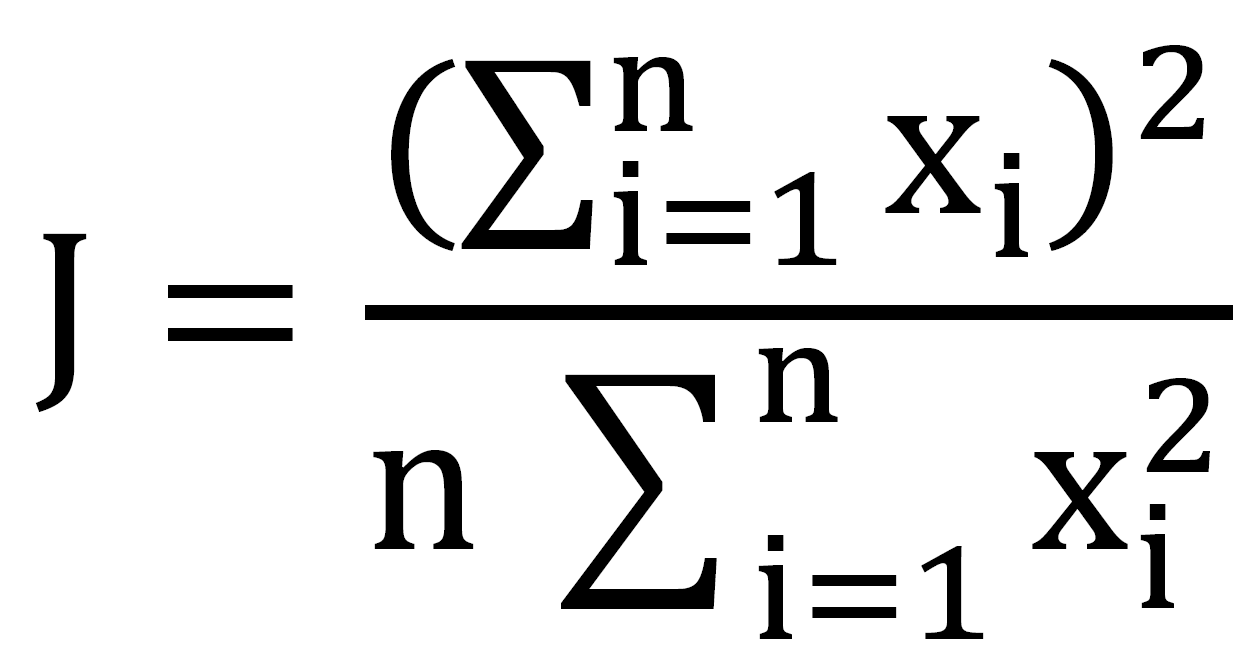
where, Xi represents the throughput of slice i is the number of slices.
In this section, the performance evaluation of the proposed Deep Reinforcement Learning (DRL)-based network slicing optimization framework, in diverse network conditions, is presented. These are compared to traditional baseline methods such as Static allocation, Round-robin scheduling and heuristic-based methods.
Convergence Behavior of the DRL Model
The evaluation of the training performance of the DRL agent is by tracking the total reward achieved during training episodes. The findings show that the model stabilizes gradually when the number of episodes reaches about 600-800, which means that learning behavior is stable. Experience replay and adaptive policy update are also involved in minimizing variance and speeding up the convergence. Figure 2 shows the convergence behavior of the proposed DRL model.
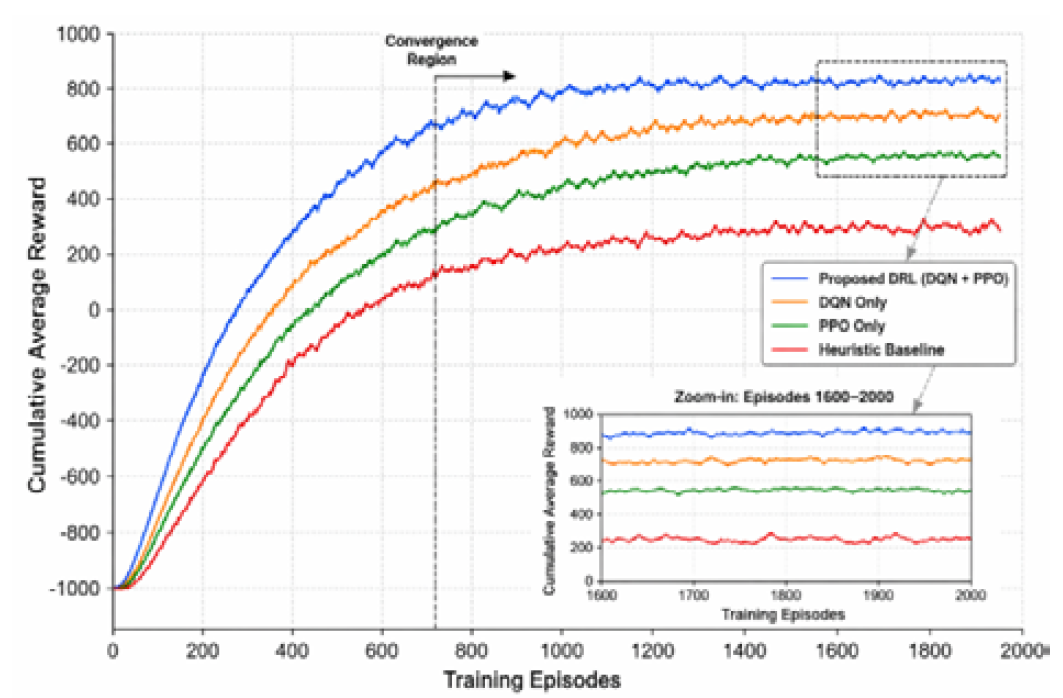
Figure 2: Convergence Behavior of the DRL Agent During Training
Throughput Performance
The suggested DRA-based architecture is much more effective in terms of the overall system throughput as it can dynamically allocate resources in accordance with the current network conditions. Figure 3 shows the comparison of means of throughput of the system in different numbers of users.
Improvement over static allocation: ~+18%
Improvement over round-robin: ~+12%
Improvement over heuristic methods: ~+9%
Such an improvement can be mainly explained by the smart allocation of high-demand slices (e.g., eMBB) without compromising on the resources of latency-sensitive services.
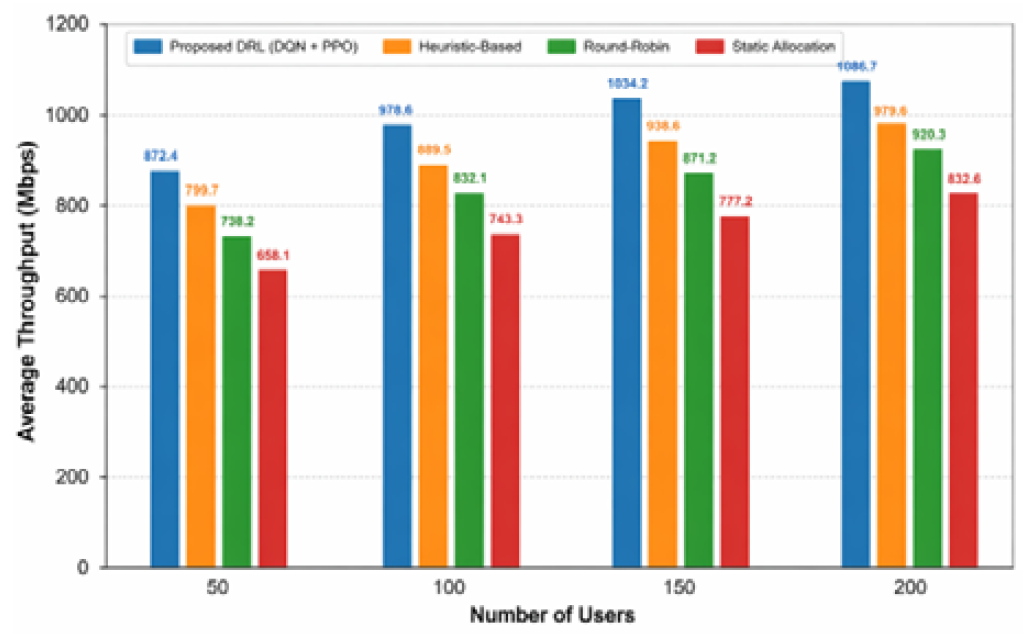
Figure 3: Comparison of Average System Throughput of the Proposed DRL-Based Framework with that of the Baseline Methods at Various User Densities
End-to-End Delay Analysis
The reduction in latency is a key need and particularly in the URLLC services. Significant improvements are observed with the proposed framework:
Compared to a static allocation: ~-28%
Reduction over round-robin: ~-21%
Reduction over heuristic techniques: ~-15%
The DRA agent is successful in reducing congestion and queues since it actively repurposes resources to delay-sensitive slices. Figure 4 displays the latency performance of the system.
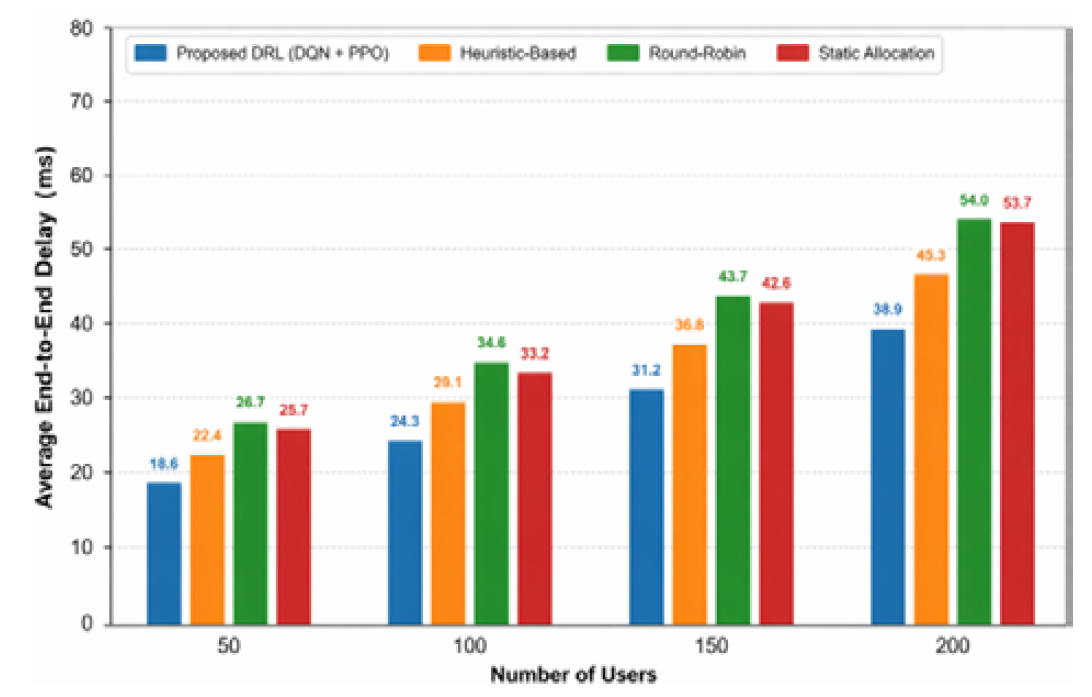
Figure 4: Average End-To-End Delay Comparison Under Different Numbers of Users
Packet Loss Ratio (PLR)
The adaptive resource allocation policy helps to enhance the reliability of the network, PLR reduction:
Static allocation: -22%
Round-robin: -17%
Heuristic: -12%
The reduced loss of packets is ensured through balanced use of resources and non-overloading. The packet loss performance is illustrated in Figure 5.
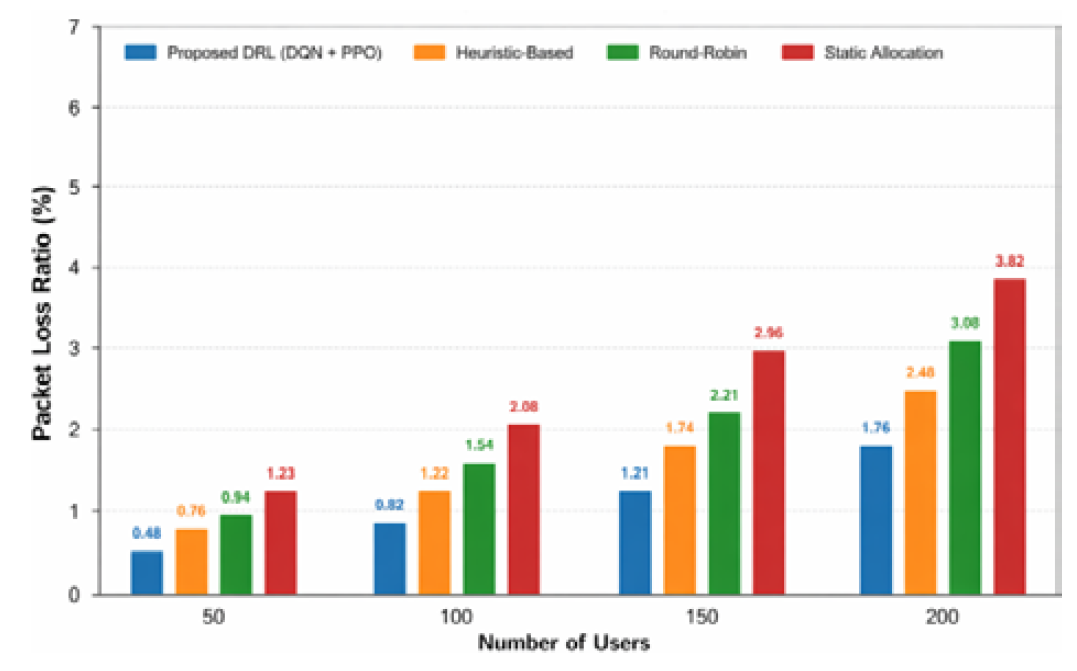
Figure 5: Packet Loss Ratio (PLR) Comparison of the Proposed DRL-Based Framework and Baseline Methods Under Varying User Loads
Spectral Efficiency
The suggested approach shows improved spectrum usage:
Improvement over static allocation: ~+14%
Improvement over round-robin: ~+10%
This implies that DRL model makes the best use of the available bandwidth without affecting the quality of service. The index of fairness among slices is assessed based on the index of Jain as in Figure 6.
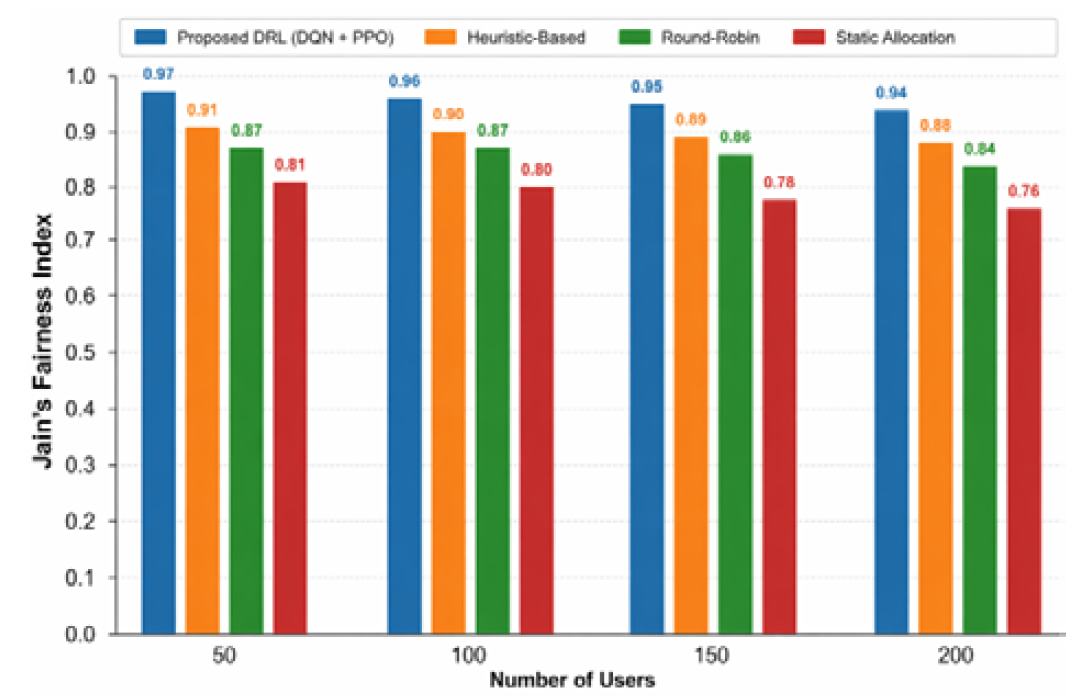
Figure 6: Jain’s Fairness Index Comparison Across Different Methods
Fairness Evaluation
Fairness between slices is measured using the Fairness Index of Jain. The degree of fairness of the proposed framework is high:
DRL-based method: ~0.94-0.97
Static allocation: ~0.82
Round-robin: ~0.88
Heuristic: ~0.90
The findings affirm that the model balances the distribution of resources and still achieves optimal performance. Figure 7 shows the spectral efficiency with different traffic loads.
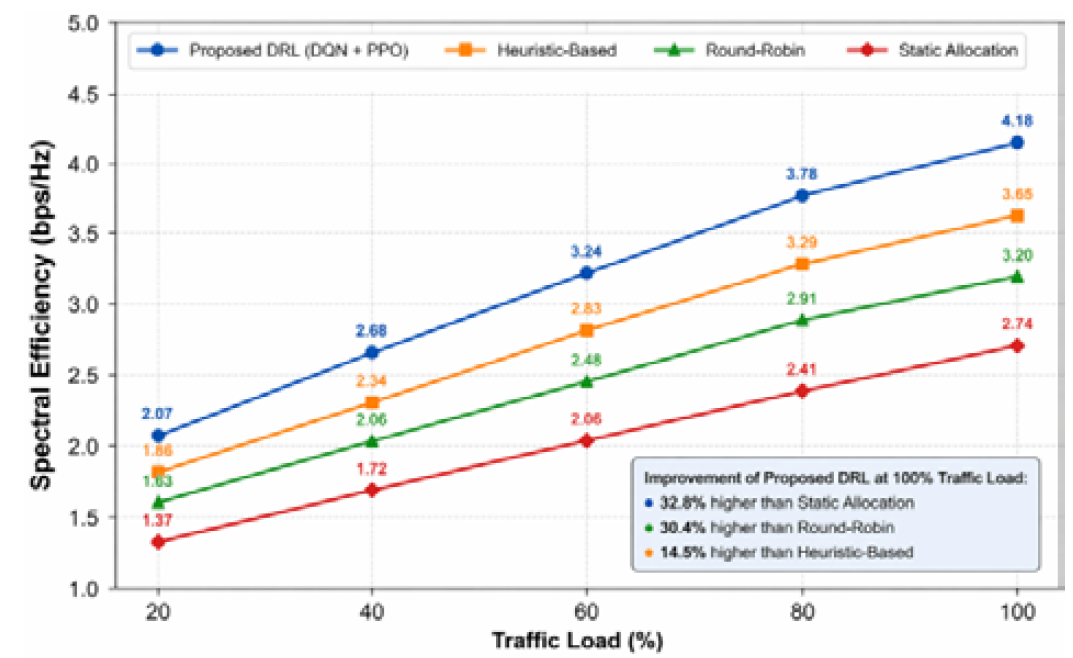
Figure 7: Spectral Efficiency Comparison Under Different Traffic Load Conditions
The experimental findings are clear evidence of the superiority of the suggested DRL-based network slicing optimization framework. In contrast to the traditional methods, the DRA model never stops learning about the environment and modifies its decision-making plan to maximize various conflicting goals, such as throughput, latency and fairness. DQN combined with PPO allows
managing discrete and continuous decisions related to the allocation of resources efficiently and the framework can be scaled in the future with 6G networks. Moreover, the capability to work in real-time dynamic environments also indicates its practical use in next-generation communication systems.
The model, however, brings extra computational costs in training, which can be optimized to use in resource-constrained edge deployments. Scalability and efficiency can further be improved by using lightweight DRL models and distributed learning methods like federated learning as a future research possibility.
This paper proposed a smart approach to network slicing optimization in 5G/6G networks using Deep Reinforcement Learning (DRL). The proposed framework treats the resource allocation problem as a Markov Decision Process and hence allows for adaptive decision-making to deal with the dynamic nature of the network. The use of DRL enables the effective optimization of performance indicators such as throughput, delay, spectral efficiency and fairness. Simulations showed that the proposed approach achieves superior performance compared to traditional resource allocation approaches by improving resource efficiency, decreasing end-to-end delay and enhancing the level of QoS satisfaction across diverse network slices. These results validate the benefits of applying artificial intelligence in next-generation network management to tackle complex and dynamic scenarios. However, the proposed model introduces learning complexity, which could be a constraint for real-time applications in compute-limited environments. Hence, future research should explore lightweight DRL models, edge intelligence and federated learning to extend distributed learning and optimization to 6G networks.
Nleya, S.M. et al. “Beyond 5G: The Evolution of Wireless Networks and Their Impact on Society.” Advanced Wireless Communications and Mobile Networks-Current Status and Future Directions, IntechOpen, 2025.
Baptista, C.S. and D. Nunes. “Digital Ecosystems and Their Influence on Business Relationships.” Review of Managerial Science, vol. 20, 2026, pp. 29-51.
Popovski, P. et al. “5G Wireless Network Slicing for eMBB, URLLC and mMTC: A Communication-Theoretic View.” IEEE Access, vol. 6, 2018, pp. 55765-55779.
Mazhar, T. et al. “Quality of Service (QoS) Performance Analysis in a Traffic Engineering Model for Next-Generation Wireless Sensor Networks.” Symmetry, vol. 15, 2023.
Ma, Z. et al. “High-Reliability and Low-Latency Wireless Communication for Internet of Things: Challenges, Fundamentals and Enabling Technologies.” IEEE Internet of Things Journal, vol. 6, 2019, pp. 7946-7970.
Shuford, J. “Deep Reinforcement Learning Unleashing the Power of AI in Decision-Making.” Journal of Artificial Intelligence General Science, vol. 1, 2024.
Mienye, I.D. et al. “Deep Reinforcement Learning in the Era of Foundation Models: A Survey.” Computers, vol. 15, 2026.
Cui, Z. et al. “A Review of Multi-Agent Deep Reinforcement Learning for Resource Allocation in Beyond 5G Network Slicing: Solutions, Challenges and Future Research Directions.” PeerJ Computer Science, vol. 12, 2026.
Ebregbe, D. and S. Ekolama. “Telecommunication Network Optimization of 5G and Beyond: Enhancing Performance, Scalability and Efficiency.” 2026.
Javadpour, A. et al. “A Reinforcement Learning Approach to Virtual Network Embedding Problems in 5G Networks.” IEEE Transactions on Network Science and Engineering, 2026.
Cai, Y. et al. “Deep Reinforcement Learning for Online Resource Allocation in Network Slicing.” IEEE Transactions on Mobile Computing, vol. 23, 2023, pp. 7099-7116.
Malta, S. et al. “Optimizing 5G Network Slicing with DRL: Balancing eMBB, URLLC and mMTC with OMA, NOMA and RSMA.” Journal of Network and Computer Applications, vol. 234, 2025.
Azimi, Y. et al. “Mobility Aware and Energy-Efficient Federated Deep Reinforcement Learning Assisted Resource Allocation for 5G-RAN Slicing.” Computer Communications, vol. 217, 2024, pp. 166-182.
Wang, R. et al. “Energy-Aware Design Policy for Network Slicing Using Deep Reinforcement Learning.” IEEE Transactions on Services Computing, vol. 17, 2024, pp. 2378-2391.
Guo, S. et al. “Towards Transparent 6G AI-RAN: A Survey on Explainable Deep Reinforcement Learning for Intelligent Network Slicing.” Journal of Information and Intelligence, 2025.
Karahan, S.N. et al. “Realistic Performance Assessment of Machine Learning Algorithms for 6G Network Slicing: A Dual-Methodology Approach with Explainable AI Integration.” Electronics, vol. 14, 2025.
