
+91 6002993949
submission@iarconsortium.org
Open Access
ISSN (Print) : 2708-5155
ISSN (Online) : 2708-5163
The eye is our primary sensory organ, providing the primary channel for perceiving the world around us. Daily tasks become difficult for people with visual impairments, as they rely on their senses of touch, hearing, smell and taste to navigate their environment. Modern technology has provided smart tools and applications to assist the visually impaired. This project draws its inspiration from how the human eye, along with brain cells, analyzes images to identify objects. The system uses a Raspberry Pi with a built-in camera, the Picamera2 library, to capture real-time images during execution. The system is based on the SSD MobileNet V3 algorithm, which applies deep learning through convolutional neural networks (CNNs) for object recognition. The COCO dataset serves as the basis for training the model, demonstrating superior performance in object recognition across different categories. The OpenCV library was also used to enhance detection accuracy, while the NumPy library enables complex calculations, including distance estimation using focal length proportional laws. The audio feedback generation is based on the pyttsx3 library, which converts the names of recognized objects, along with distances, into spoken words. These techniques allow the system to learn automatically and improve its performance over time, resulting in better recognition accuracy. The Raspberry Pi acts as the central processing unit, managing all tasks, from image capture to analysis and response generation. The system is flexible and scalable, allowing for expanded features with text recognition and color identification capabilities. This advanced technology represents a breakthrough in the field of assistive technology, enhancing the independence of visually impaired people and supporting their active participation in various environments. This solution provides a real-time object recognition system.
The Smart AI Vision Aid project aims to develop a novel system that enables visually impaired people to perform their daily activities autonomously. The system employs real-time object detection tools with audio output to enhance user independence and reduce their need for human assistance. The system uses computer vision technologies with artificial intelligence capabilities and audio feedback to create a simple device that welcomes all users.
This work aims to address three main issues visually impaired people encounter during object identification and navigation of unfamiliar areas and reading printed texts [1]. Object detection proved its capability to provide practical support for visually impaired people successfully.
The proposed system uses a camera to acquire real-time images which are then processed by pre-trained AI algorithms before sending the processed data to the user as an audio output, the combination of text recognition with audio conversion delivered better accessibility benefits[2]. The method placed priority on implementing computer vision technology to detect objects together with obstacles. The project uses advanced detection algorithms as an enhancement to this system for achieving better performance and accuracy.
The project must provide effective navigation with obstacle detection capabilities because its detection algorithms announce any nearby objects or barriers which protect user safety. The project utilizes modern image processing technology which provides both performance strength when dealing with challenging environments and accurate real-time directions. Through integrating findings from existing research and modern technological implementations the Smart AI Vision Aid can deliver an effective assistance tool that empowers blind individuals with improved quality of existence [3,4].
Figure 1: The main components of AI
A computer or system that mimics human intellect to do tasks in the real world is called artificial intelligence (AI). It creates computers that can process information by simulating the human mind. arranging and carrying out tasks in accordance with the information supplied. AI makes it possible for the system to learn from data and gain the knowledge and abilities necessary to successfully handle problems [5]. The algorithm may use the available data to improve itself iteratively. AI systems can solve problems efficiently because they can learn from their past experiences. AI has found important uses in a number of fields, including recommendation systems, games, human speech recognition, automated driving cars, improved online search engines and healthcare [6]. Figure 1 illustrates AI's fundamental component.
Around 1950, artificial intelligence (AI) began to appear in computer science. Due to the widespread use of AI equipment in industry, more study is being done in engineering fields as natural Science, medicine, disease diagnosis and natural language processing (NLP) [7].
Several studies with different problems have been carried out to realize the areas of object detection. A review of some of these fields is provided in this section.
Srivastava et al. [3] designed a small, wearable and versatile device that provides security features to assist visually impaired people in their daily tasks. The system, which requires further development, will support visually impaired people, according to the planned design, by detecting obstacles and classifying scenes. The proposed methodology is based on a Raspberry Pi 4B, a camera, an ultrasonic sensor and an Arduino board mounted on a person's joystick. Scene images are captured and preprocessed using the Viola Jones algorithm and TensorFlow for object detection. These techniques are used for object detection[4].
Rahman et al. (2023) develops a smartphone-based object recognition system that can alleviate the monetary transactions, mobility issues, etc. for visually impaired people (VIP). Due to the usage of a single smartphone, the design of the system remains straightforward and it requires no extra hardware. Alongside, it is convenient to adapt to the human body. Then, to recognize the object in real time, it exploits Single Shot Detector (SSD), Convolutional Neural Network (CNN) and TensorFlow-lite (tflite) that classify trains as well and tests the object and supports the platform, respectively, for this purpose. First, it creates a dataset in the format of the COCO dataset. Then, it labels the recognized object by a text-to-speech conversion method and sends it to the VIP via Bluetooth technology [8].
Kumar et al. [9] presented a system that aims to provide a simple, easy-to-use, practical, economical and effective system for visually impaired people. The target of this system is to establish a detection process which utilizes a camera as real-time input device to identify present objects followed by object communications through smartphone-linked headphones. The system needs either speakers or headphones to give object information that helps visually impaired persons. Through its functionality this system enables identification of objects in open and enclosed spaces which enables visually impaired persons to carry out their life activities and perform occupations [9].
Srivastava et al. [4] described the Smart glove. This glove can detect any obstacle in the Path of blind people and can warn them. So that it ensures their safety. Also, it works as an artificial eye for them. This glove can extract text from any image that contains text and can convert text into speech. So that blinds can easily hear the text which they cannot see [3].
Al-Najjar et al. [10] aimed to create an intelligent system that mimics the human eye, transmitting different scenes and images to the brain. The brain, in turn, analyzes the images or scenes and based on previously stored information, identifies surrounding objects. To do this, we used a small device that works similarly to the human brain, called the Raspberry Pi. This small device analyzes images and scenes using a camera, which transmits the images to the small device. The analysis process then begins using complex algorithms known as neural networks. This network analyzes images into segments and compares them to the most important characteristics of objects in the images linked to a database, through which the images are compared. When the characteristics match the mathematical equations programmed in Python, the objects in the image are detected. Finally, the sound of each tool in the database is called and a message is sent informing the blind person of the tools in front of them [10].
Embedded systems serve as essential components of human life by designers who create them for specific operational purposes. Present-day popularity of embedded systems exists because these devices feature small dimensions and affordable construction along with straightforward design approaches. The utility of embedded systems grows continuously in modern times as they dominate various devices including household appliances and equipment [11]. Users can now control various aspects of their home remotely through the Internet of Things (IoT) intervention which enables mobile device management of house lights even when absent [12]. A computer system may identify patterns, improve predictive accuracy and repeatedly improve its performance through experiential learning thanks to machine learning (ML), a computational paradigm. without requiring specific programming. An AI-driven application is built using machine learning. ML techniques are used to carry out the process [7]. Several algorithms are used in machine learning, including Support Vector Machines, Random Forests and Decision Trees. Also, the Deep learning (DL) is a branch of machine learning that models intricate patterns in data using multi-layered neural networks. DL uses multiple layers to extract features from raw data to identify variables. relevant to the input data. Numerous algorithms are included in DL, such as Recurrent Neural Networks (RNN) and Convolutional Neural Networks (CNN). Convolutional networks, a type of artificial neural network, are used by DL. Previously, ML's use was limited by its inability to efficiently handle raw input data. By leveraging its ability to handle enormous volumes of data, DL has effectively overcome this limitation, making it a very effective and worthwhile machine learning technique. Advances in computer hardware technology have sped up DL's development. Expertise in feature extraction was necessary to convert the raw data into a format that the machine's subsystem could use to precisely recognize and classify the unprocessed data [13].
Object Detection
Finding and Identifying Objects One of the most important tasks in computer vision is object detection, which is the process of locating and recognizing entities in a video or image. By combining characteristics from object localization and image classification, it enables systems to define bounding boxes around an object in addition to determining its category. This technology is the foundation of many modern applications, such as facial recognition, augmented reality, autonomous driving and security monitoring [14].
Object discovery is the process of finding and identifying objects in an image without first comprehending the object categories. This involves locating every possible item-containing area in an image, occasionally using unsupervised or lightly supervised learning techniques. When the system needs to dynamically adjust to new objects or when the item categories are not predefined, the importance of object discovery is crucial. Techniques such as region proposal networks (RPNs) are frequently used to produce candidate object areas, which can then be the topic of further investigation [15,16].
In proposed system, which is based on "Detection for the Blind Using Artificial Intelligence", computer vision algorithms were used to detect objects and convert the information into audio signals to help with navigation. In this area, detection algorithms were used. Computer vision systems can provide real-time assistance by analyzing images and identifying objects [17].
A multi-category single-shot detector that is both quick and far more accurate than the previous state-of-the-art for single-shot detectors (YOLO), in fact, it is on par with slower methods that use explicit region suggestions and pooling (such as Faster R-CNN). Using tiny convolutional filters on feature maps, SSD's main function is to forecast category scores and box offsets for a predetermined set of default bounding boxes. generate predictions of various scales from feature maps of various scales and explicitly split predictions by aspect ratio in order to achieve high detection accuracy. The speed vs. accuracy trade-off is further improved by these design elements, which result in straightforward end-to-end training and good accuracy even on low quality input images. The experiments compare a variety of modern state-of-the-art methods and involve timing and accuracy analysis on models with different input sizes evaluated on PASCAL VOC, COCO and ILSVRC [18].
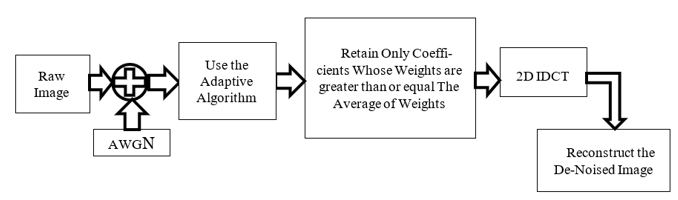
Figure 2: SDD Architecture [18]

Figure 3: SSD Original Prediction Layer [19]
In Figure 2a During training, SSD requires simply an input image and ground truth boxes for every item. assess a small collection (for example, 4) of default boxes with varying aspect ratios at every position in many feature maps with various scales using a convolutional approach (e.g. and in (b) and (c)). forecast the shape offsets and the confidences for every object category for every default box. first compare these default boxes to the ground truth boxes during training. for instance, matched two default boxes with the dog and two with the cat; the latter are regarded as negatives and the former as positives. The weighted sum of the localization loss and confidence loss (e.g. SoftMax) is the model loss [18] as shown in Figure 3.
Real-Time Voice Feedback
Converting Visual Information into Audio Guidance for the Visually Challenged
Real-time voice feedback systems play a crucial role in assisting visually impaired individuals by transforming visual information into comprehensible audio output. This technology enables users to interact with their environment more effectively, fostering independence and safety [20].
Definition of Voice Feedback Systems
They have become a significant part of assistive technologies as they enable users to receive auditory information based on the visual data they collect in real time. These systems use cameras or sensors to monitor visual stimuli, process the information and relay that through either vocalization or audio signals that instruct the user. These systems, by providing instant, accurate audio feedback, boost a visually impaired person's capacity to get around their environment and do everyday activities [21].
Key Components of Text-to-Speech (TTS) Systems
A Text-to-Speech (TTS) system is a core component of voice feedback systems. It converts digital text into human-like speech, making information accessible through audio output. The primary components of a TTS [22] , system include:
Integrating Voice Feedback with Object Detection
Integration of voice feedback systems with object detection technologies would greatly increase the potential of assistive devices for visually impaired users. It empowers multi-sensory integration, where devices identify objects in the world and offer real-time audio descriptions. For instance:
Camera Input
A camera continuously shoots the environment. A very common device for this process is Raspberry Pi with the Picamera2 module [24].
Object Detection Model
The image data is processed using models for object detection such as SSD (Single Shot Multibox Detector) or YOLO (You Only Look Once). These models detect objects and their locations in the camera frame [7].
Audio Output
After the detection of an object, the system translates that identification to verbal language. For instance, on detecting a chair, the system says “Chair ahead” [24].
Enhancing Real-Time Feedback with Raspberry Pi
Raspberry Pi-based devices have become popular for assistive technologies because they are inexpensive and flexible. Real-time voice feedback has been implemented in many projects which has shown to enhance accessibility [24]. The systems produce audio output through libraries which include speak, pyttsx3 and Google Text-to-Speech (gTTS) on the Raspberry Pi. The systems enable object detection through computer vision libraries such as OpenCV and TensorFlow to provide verbal feedback.
Practical Implementation Example
For instance, a user approaching a street intersection might hear:
The combination of real-time voice feedback with object detection enables assistive devices to provide visually impaired users with complete surroundings information at appropriate times.
The Smart AI Vision Aid project follows a descriptive research design. The project selected this approach because it needed to observe, analyze and describe the system's functionality in real-world scenarios. Through the descriptive research design, researchers can thoroughly study how the object detection system works to identify objects and give immediate audio feedback to visually impaired users. The Smart AI Vision Aid project required hardware and software tools which were chosen for their ability to make the system functional and accurate and reliable. The following is a detailed description of the tools used and the reasons for their selection.

Figure 4: Raspberry Pi (Model 4B)

Figure 5: OV5647 Camera module
Raspberry Pi (Model 4B)
The Raspberry Pi is a small, affordable and powerful single-board computer that acts as the core processing unit for the project. It was chosen for its versatility, low power consumption and ease of integration with various sensors and peripherals.
OV5647 Camera Module
The OV5647 is a 5MP CMOS camera sensor, widely used with custom camera modules for the Raspberry Pi. It was used in early versions of the Raspberry Pi Camera Module but is not officially supported on the Raspberry Pi 4 and later without custom drivers. It is used with the PiCamera2 module to capture real-time images and videos. It works well with the Raspberry Pi and offers high-quality image capture, which is important for accurate object detection.
Earbuds
Portable headphones are used to provide real-time audio feedback to the user. The speaker makes sure that the system gives clear instructions and alerts. These speakers are Bluetooth earphones for ease of use and guaranteed results, in addition to their size that can be taken anywhere. without being disturbed by their size.
Figure 6: Earbuds (Bluetooth earphones)
Figure 7: Power Supply
Power Supply
A reliable power supply is important to ensure that the Raspberry Pi and its connected peripherals keep running without interruption. F is a rechargeable Li-ion battery for this purpose, we used a LC 18650 battery 3800mah 3.7 v, which
To achieve the intended goal of the proposed system, several software tools and systems were used, including the following
Operating System
This system relies on the Raspberry Pi's own operating system, allowing us to operate the Raspberry Pi and manipulate its options to identify devices, such as the camera, Bluetooth and headphones. It also allows us to install the necessary tools and programs. The Raspberry Pi system automatically includes Python its main programming language. The project selected Python because it provides easy-to-use syntax alongside extensive libraries and robust support for machine learning and computer vision tasks
Libraries
Installed the Picamera2 library, which captures images in real time , The Picamera2 library is used to control the camera module and capture images in real time. It provides a simple and efficient interface for image processing tasks. We then installed the OpenCV library OpenCV functions as a computer vision library that enables image processing and object detection and distance estimation. The system depends on OpenCV to achieve better object detection accuracy and enhanced performance. This library enhances the functionality of the Picamera2 library. The NumPy library is responsible for performing complex mathematical operations, including distance calculations. The pyttsx3 library is responsible for converting text into voice instructions, The system uses Pyttsx3 for offline functionality to operate without requiring an internet connection, In addition to the Thread library, a thread operates as an independent subprocess that runs concurrently with other processes in the program. Threading allows multiple tasks to run simultaneously without the need to complete each task before starting the next.
Algorithm Use
SSD Mobile Net V3: This algorithm relies on convolutional neural networks (CNNs) to detect objects in captured images.
Model Configuration
The model files such as: ssd_mobilenet_v3_large_coco_ 2020_01_14.pbtxt (Configuration file).
frozen_inference_graph.pb (Pre-trained weights file).
Development Environment:
The system was developed and tested using Python because it has a lot of support for computer vision and text to speech libraries.
Working Mechanism:
The mechanism of the system shows in the flowchart in Figure 7:
SSD Model with Mobile Net
The technique of object detection holds essential value within computer vision applications given its importance for accurate and fast operations on embedded Raspberry Pi devices. The model SSD (Single Shot MultiBox Detector) with MobileNet serves as an optimal solution since it delivers high performance together with reduced computational requirements which accommodates systems with limited resources. The selection of SSD centers on its capability to execute direct object detections from a single neural network without performing image segmentation because Faster R-CNN requires. Such architecture enables fast performance together with reduced computational requirements. MobileNet specializes in creating a highly efficient detection model which delivers satisfactory accuracy results. DSCs enable the model to perform feature extraction using fewer computations when processing visual data. MobileNet excels in applications using limited processing power because of its special design feature. When integrated with MobileNet the object detection model becomes efficient enough for real-world applications in security surveillance systems along with robotics and as a blind assistance tool while requiring minimal processing power and decreased energy usage
The SSD structure including MobileNet starts its object detection process through a camera stream in real time. When opening the camera, the continuous frame capture starts. The model verifies every frame for successful reception. The process termination occurs when no frame arrives. The SSD model with MobileNet receives the frame for image analysis which automatically extracts detected objects from the image. After processing by the pre-trained model, the system generates classifications and labels for the objects detected.
This information directs a choice between audio signal emission and execution of certain actions. Following decision execution, it is necessary to verify whether to terminate the camera. The process will keep receiving new frames unless it detects a stop command from the operator which triggers the complete termination of the entire operation. The program applies the SSD algorithm to section images into areas and quickly detect objects thus being well-suited for running on energy-efficient Raspberry Pi devices (Figure 8).
Canvas Distance Measurement Method
The distance between the camera and the detected object was calculated using the focal length formula. The width of the object in the captured image and its real-world width were used to estimate the distance between the camera and the object.
The Formula Used
To calculate the distance between the camera and the detected object, the following formula was used:
D = (W.f )/w
Where:
D is the distance between the camera and the object.
W is the real-world width of the object.
f is the focal length of the camera (which is determined by the camera specifications).
w is the width of the object in the captured image.
Explanation of the Formula:
Figure 8 Flowchart of the proposed system
Once these values are obtained, the above formula can be used to accurately calculate the distance between the camera and the detected object.
Canvas Text-to-Speech Conversion
The pyttsx3 library was used to convert text to speech, transforming the names of detected objects and distances into audible notifications. This method greatly helps in providing guidance for visually impaired users, enabling them to interact with their environment effectively without the need for touch or sight.
Real-time voice guidance technology deployed on Raspberry Pi OV5647 Camera demonstrates effective operational capabilities for visually impaired users. The evaluation and experimentation process produced multiple essential findings which demonstrate how real-time voice guidance systems can help visually impaired people. The Raspberry Pi system with an OV5647 Camera and SSD algorithm enables simple object recognition, which has resulted in better accuracy for object and surrounding area detection. The system uses the pyttsx3 library to generate precise voice commands that the user can understand. The instructions assist blind users to move through their environment and engage with objects in their space. A measurement function based on the Canvas tool calculates camera-object distance to assist users in detecting approaching objects. The system results discussion reveals multiple areas where the system can be improved and enhanced. The system needs further optimization of hardware components and software algorithms to enhance its energy efficiency and robustness and scalability capabilities. Additionally, system considerations.
Figure 9: Person Detection
Figure 10: Chair Detection
In Figure 9, the algorithm created a frame around the detected object. After creating the frame around the detected object, it entered it into the Coco Names database and discovered that it was a person. It measured the distance between the camera and the object using the focus and equation of the camera and discovered that it was 1.75 m). It converted this discovery (PERSON) and the distance (10.75 m) into voice messages through the library pyttsx3 and transmitted it to the earphone worn by the blind person.
Figure 11: Clock Detection
In Figure 10, the algorithm created a frame around the detected object. After creating the frame around the detected object, it entered it into the Coco Names database and discovered that it was a chair. It measured the distance between the camera and the object using the focus and equation of the camera and discovered that it was (0.69m). It converted this discovery (CHAIR) and the distance (0.69 m) into voice messages through the library pyttsx3 and transmitted it to the earphone worn by the blind person.
In Figure 11, the algorithm created a frame around the detected object. After creating the frame around the detected object, it entered the Coco Names database and discovered that it was a clock. It measured the distance between the camera and the object using the focus and equation of the camera and discovered that it was 8.87m). It converted this discovery (CLOCK) and the distance (8.87 m) into voice messages through the library pyttsx3 and transmitted it to the earphone worn by the blind person.
In Figure 12a-b, the results show that the system is effective and works efficiently and reliably and thus, we have achieved the project goal of detecting surrounding objects and then returning audio instructions on what this object is, in addition to calculating the object’s distance from the camera well.
The text-to-speech conversion is important in giving a real and effective user experience for blind or visually impaired people. Users are empowered to receive instant and realistic guidance by converting data into audio feedback, such as the detected objects and their distances from the camera. These instructions may include:
Figure 12: (a) Project Results and (b) Person Detection
| Table 1 Distance calculation accuracy table | |||
| ID | Item | Distance in system | Real Distance |
| 1 | Person | 1.75 m | 1.77m |
| 2 | Chair | 0.69m | 0.71m |
| 3 | Clock | 8.78m | 8.50m |
| 4 | Bead | 3.22m | 3.21m |
| 5 | Cell phone | 0.50m | 0.50m |
| 6 | Laptop | 0.66m | 0.65m |
| 7 | Book | 1.10m | 1.11m |
The feature enables visually impaired users to navigate their environment independently which improves their daily lives.
The Figure 13 shows the final shape of the proposed project and the advantage of this shape is the low weight, about 300 g and easy to wear and very comfortable. Cause it is on the head, the camera has a good angle of view.
Table 1 that the proposed system calculated the distance between the device and the detected object. Some error percentages appeared in the calculation and this is a natural matter due to the movement of the camera in addition to the difference in the focal length that it relied on in calculating the distance (as we discussed in the third chapter) and other factors that affect the accuracy of the calculation, such as the intensity of lighting.

Figure 13: The Final Shape
| Table 2: Speed of element discovery | ||
| ID | Items | Discover it in a second |
| 1 | Person | 2 s |
| 2 | Chair | 0.85 s |
| 3 | Clock | 1s |
| 4 | Book | 0.90 s |
| 5 | Bead | 1 s |
| 6 | Cell phone | 0.5 s |
| 7 | laptop | 1.5 s |
Table 2 shows the speed of the proposed system’s detection of elements within the surrounding environment, as the detection speed depends on the processing speed of the adopted algorithm (SSD). This algorithm is not fast enough compared to Yolo, but it gives accurate results.
| Table 3: Element detection accuracy table | ||
| ID | Items | Element detection accuracy |
| 1 | person | person |
| 2 | Book | Book |
| 3 | Clock | Clock |
| 4 | Laptop | laptop |
| 5 | Chair | Chair |
| 6 | Bead | Bead |
| 7 | Apple | Heart |
| 8 | Orang | Orang |
| 9 | Cell phone | Cell phone |
| 10 | Car | Car |
| 11 | Remote | Cell phone |
| 12 | Tv | Tv |
| 13 | Bicycle | Bicycle |
| 14 | Cat | Cat |
| 15 | Dog | Dog |
| 16 | Pool | Tv |
| 17 | Cake | Cake |
Table 3 shows the accuracy of object detection, where the system showed a low error rate compared to the correct detection. Here got an accuracy of up to 90%, thus proving the worthiness of our system for efficient use in the environment of the blind. In addition, the system trained on our own indoor environment, which may be similar to the environment of the blind person and trained the model on the most important objects and those most surrounding the blind person.
The research project creates an advanced system that enables visually impaired individuals to complete daily activities while navigating without needing human support. Real-time audio guidance from Computer Vision technology and Text-to-Speech conversion enables user independence while improving their quality of life. The model operates with a Raspberry Pi device that contains a camera, which uses the Picamera2 library to capture images in real time. The SSD Mobile Net V3 algorithm analyzes images through Convolutional Neural Networks (CNNs) to perform object detection tasks.
The COCO dataset serves as the training material for this model because it efficiently detects multiple objects. The system employs OpenCV library functions to enhance detection precision and speed up processing operations on Raspberry Pi hardware. The system uses NumPy for executing complex mathematical operations to calculate the camera-object distance by analyzing the relationship between focal length and object dimensions in the captured image. The pyttsx3 library serves as the text-to-speech solution for the system to provide audio guidance. The system configuration provides object name announcements and distance information but avoids repeated announcements unless there is substantial distance variation. The system design reduces unnecessary audio output for users. The research faced several technical challenges, including:
The research shows how AI and Computer Vision technologies can help people with special needs and how this could lead to the development of intelligent tools that help them be more independent.
We are pleased to present this work on (Smart AI Vision Aid: Real-Time Audio Guidance for the Visually Impaired), to all those who have lost the gift of sight. We express our deep gratitude to everyone who contributed their valuable time and guidance in my time of need. It is a great honor for me to undertake this work in the esteemed Department of Computer Science, College of Computer Science and Mathematics, Tikrit University, Iraq.
