
+91 6002993949
submission@iarconsortium.org
Open Access
ISSN (Print) : 2708-5155
ISSN (Online) : 2708-5163
This paper resents an enhanced scheme utilizing Rate-Distortion Optimized Quantization Index Modulation (RDO-QIM) for image watermarking, emphasizing its ability to balance imperceptibility, robustness and computational efficiency. Unlike conventional QIM-based methods that embed uniformly across all transform coefficients, the proposed approach employs a Lagrangian Rate-Distortion (R-D) criterion to adaptively quantize the coefficients. This dynamically balances embedding distortion and payload rate, achieving superior visual quality without compromising robustness. The algorithm jointly exploits cosine and wavelet coefficients to capture both local and global image features, while a perceptual energy/saliency model directs embedding toward visually tolerant regions. Experimental results on the RSICD dataset and eight standard images confirm significant improvements over a recently published DCT/DWT domains baseline, with PSNR exceeding 50 dB and SSIM above 0.99 on average, alongside a notable reduction in bit error rate under various attacks. Although the method introduces moderate computational overhead (≈25% higher runtime) due to the R-D optimization loop, it maintains full blindness and requires no side information for watermark extraction. These findings demonstrate that RDO-QIM is a highly practical and efficient solution for secure, high-fidelity multimedia watermarking.
In modern communications engineering, digital watermarking [1] is a critical technique for protecting data integrity, ownership and authenticity in multimedia transmission systems. Particularly in image-based communication, embedding auxiliary information directly into media content supports secure content delivery, copyright enforcement and tamper detection without requiring additional bandwidth.
Traditional watermarking schemes using Discrete Cosine Transform (DCT) [2], Discrete Wavelet Transform (DWT) [3] and spatial-domain [4] embedding provide reasonable robustness but they often fail to optimize the trade-offs between payload, imperceptibility and resistance to attacks-especially in bandwidth-limited or noisy communication channels [5]. A successful watermarking system in this context must encode data such that it survives transmission errors and compression artifacts while remaining imperceptible to end users. Achieving this balance is a central challenge in communications signal design. Classical Quantization Index Modulation (QIM) [6,7] based watermarking offers theoretical resilience against additive noise, making it a compelling choice for signal embedding in communication pipelines. However, conventional QIM typically uses a fixed quantization step and uniform coefficient selection, leading to unnecessary distortion in sensitive regions and suboptimal performance in varying channel conditions. These systems often lack an adaptive mechanism that considers perceptual quality or channel characteristics during embedding.
This paper revisits QIM through the lens of Rate-Distortion Optimized (RDO) theory, a cornerstone of communications engineering. The proposed RDO-QIM model formulates watermark embedding as a Lagrangian optimization problem, balancing distortion against expected robustness. Embedding parameters such as quantization step size and coefficient weighting are adjusted in real time based on image content, yielding a single-pass system that avoids the high computational cost of iterative embedding. This approach brings QIM-based watermarking closer to the practical demands of robust multimedia communications, offering strong performance with minimal complexity. The main contributions of this paper are summarized as follows:
Full blind detection with side information reduction, compared to a recently published scheme, by almost one hundred percent
A unified RDO-QIM model that explicitly minimizes the trade-off between embedding distortion and robustness using a Lagrangian objective function
Adaptive coefficient selection in DCT-DWT hybrid domains based on local saliency and energy metrics
A single pass embedding process optimized to balance imperceptibility and payload capacity without residual feedback loops
Comprehensive evaluation using RSICD dataset images, with quantitative comparison to recently published article. In addition, eight standard images are also evaluated
Full complexity analysis and runtime measurements showing real-time feasibility for images under consideration
The rest of the article is arranged as follows. Introduction written in Section I, Section II contains Literature review, Methodology is written in Section III, Result analysis presented in Section IV, followed by conclusion and future work.
Although several approaches have been proposed for watermarking schemes, the cosine and wavelet-based methods remain strong baselines. In Chen et al. [2], The paper embeds a binary watermark in mid-band DCT coefficients using linear modulation, aiming for imperceptibility/robustness balance. Experiments used standard benchmark images across common signal-processing attacks. Reported results include high imperceptibility (Peak Signal-to-Noise Ratio (PSNR)) and robust metrics (Normalized Cross-Correlation (NCC), Bit Error Rate (BER)) across noise, filtering and compression. Nevertheless, tests are on a small set of classical images; resilience to geometric desynchronization (rotation/ scale/crop) and large-scale datasets or diverse content types (e.g., color, HDR) remain underexplored. Medical‑oriented Slantlet and SVD (Singular Value Decomposition) hybrids with nature‑inspired optimization demonstrate high PSNR and Structural Similarity Index (SSIM) at modest payloads [8]. DWT‑DCT‑SVD fusions with biometric watermarks report blind recovery across common attacks [9] and spatial‑domain variants using block‑wise matrix 2‑norm target robustness without transform overhead [10]. PLOS‑ONE reported spread‑spectrum embedding in non‑overlapping blocks with favorable JPEG/noise robustness at competitive PSNR [11].
Robustness to resampling, scaling and cutting is improved by combining DWT‑DCT embedding with learned resampling‑factor estimators and Y‑channel templates, evaluated on RAISE, BOSS and Dresden databases [12]. In Wang et al. [13], a blind DWT watermark with Hessenberg‑QR (please note that QR is not an abbreviation by itself, rather it is well-known by this name as a matrix decomposition approach) achieves very high imperceptibility (PSNR≈70 dB) and strong robustness but with higher embedding time for medical video. In Khassaf and Ali [14], a hybrid multilevel text protection system that combines AES-GCM encryption with DWT-DCT-SVD-based steganography to securely hide ciphertext inside color remote sensing images while preserving high visual quality and robustness is proposed. The method operates in the Y/Cb/Cr color space and embeds data in the HL sub-band of the Y channel after Gaussian blurring, Canny edge detection and zigzag-based selection of robust mid-frequency DCT coefficients guided by singular values, ensuring content-aware, attack-resilient embedding. Experiments on RSICD-based images of different sizes show successful ciphertext recovery under common attacks (Gaussian, salt-and-pepper, uniform noise, cropping, JPEG compression, scaling, histogram equalization), with high imperceptibility (PSNR up to 45.58 dB, SSIM up to 0.997, NCC≈0.999) and competitive or superior performance compared with existing DWT/DCT/SVD and encryption-based schemes. The system thus offers an effective framework for secure, authenticated and statistically unobtrusive text hiding in full-color images. Nevertheless, the system’s main drawback is the need to transmit the cover image to correctly extract the information.
Recent encoders/decoders train against differentiable attack layers. DARI‑Mark integrates attention into an end‑to‑end model for efficiency and robustness to compression, noise and cropping. Cam‑UNet introduces a learned detector for zero‑bit Fourier marks resilient to the print-camera pipeline. These models improve robustness under the trained distortions but may need domain adaptation for unseen channels.
Foundational QIM and dither‑modulation [6,7] work established the modern information‑embedding perspective. Subsequent variants include distortion‑compensated QIM, spread‑transform QIM and content‑adaptive strategies have targeted improved imperceptibility and robustness. Contemporary learned watermarking methods introduce differentiable attack models and end‑to‑end training but often trade analytical guarantees for data‑driven performance. RDO‑QIM provides a middle ground by keeping the QIM detection rule while optimizing where and how to embed bits to meet specific rate and quality targets, though practical deployment requires careful management of side information. Recent work extends QIM to multiple‑watermark embedding in vector Geographic data via multiple‑QIM to enable multi‑ownership and provenance tracking.
Our work follows the RDO‑QIM philosophy: keep a simple QIM detection rule while optimizing where and how strongly to embed to meet rate and quality targets under anticipated channels. Compared with classic transform baselines, RDO‑QIM provides tunable payload/quality trade‑offs and clear accounting for side information, though this overhead must be carefully managed.
Quantization Index Modulation (QIM)
QIM embeds message bits by nudging host coefficients (e.g., DCT/DWT or pixel values) toward one of several quantizers whose index carries the bit. At detection, the closest quantizer reveals the bit. In the scalar case, this reduces to assigning each host value to the nearest reconstruction point of either the "0‑lattice" or the "1‑lattice", with a spacing (step size) that controls the trade‑off between imperceptibility and robustness.
Rate-Distortion‑Optimized QIM (RDO‑QIM)
RDO-QIM chooses, per block or coefficient, whether and how strongly to embed based on a joint objective that trades bit‑rate (payload) against expected perceptual distortion under an assumed channel (e.g., JPEG or noise). Intuitively, textured or perceptually masked regions can carry more bits, while smooth or sensitive regions carry fewer. The optimization also tunes the quantization step to survive anticipated attacks with minimal visible change.
Quantizer Rule (Scalar Form, Textual)
Given a host coefficient x and a binary message bit b, select the nearest reconstruction point from the lattice associated with b. This can be expressed compactly as mapping x to a shifted set of uniformly spaced points, where the shift encodes b.
The decoder chooses the bit corresponding to the lattice whose nearest point is closest to the received value. Rate-Distortion objective (textual): minimize a weighted sum of distortion (e.g., squared embedding change or a perceptual proxy) and the negative of the achieved payload, subject to constraints such as maximum allowed local error and the assumed channel model. In practice, this amounts to per‑region decisions: embed/skip and step‑size selection.
Embedding Algorithm
RDO-QIM Embedding Process: The embedding process is shown in Figure 1 and consists of the following:

Figure 1: The Embedding Process of the Proposed Approach
Input: Cover image, payload bits, secret key
Parameters (Δ₀, α, β, block_size)
Output: stegoimage
Preprocessing
Convert RGB to Y Cb Cr
Extract Y (luminance) channel
Compute saliency map from Y channel by applying Haar wavelet transform to get LH, HL, HH sub-bands. Then, use HL sub-band absolute values as saliency map followed by normalization to [0,1] range
Block-based DCT
Divide Y channel into blocks
Apply 2D DCT to each block
Importance maps computation
Energy map: L2 norm of DCT coefficients per block, normalized
Saliency map: Mean saliency value per block
Adaptive quantization embedding
For each position in deterministic order:
Shuffle the coefficients order in each of the DCT blocks (to achieve: Security: prevents attackers from knowing embedding locations; Spread embedding: distributes bits across different frequency bands; Robustness: avoids concentrating all data in specific frequencies; Prevent pattern detection: no fixed scanning pattern (zig-zag, etc.))
Compute (per block) adaptive Δ = Δ₀ × (1 + α×Energy + β×Saliency)
Apply QIM: q = Δ × (floor(c/Δ) + (bit + 0.5)) (c is DCT coefficient in that block)
Replace DCT coefficient with quantized value
Continue until all payload bits embedded
Apply inverse DCT to each block
Reconstruct watermarked Y channel
Convert YCbCr back to RGB
Return stego image
RDO-QIM Extraction Process
The extraction process is shown in Figure 2 and consists of the following:

Figure 2: The Extraction Process of the Proposed Approach
Input: Stego image, number of bits to extract, secret key (the same key utilized in embedding), parameters
Preprocessing (Same as Embedding)
Convert to YCbCr, then extract Y channel
Compute saliency map
Apply block DCT
Bit Extraction
For each position in the same deterministic order:
Compute adaptive Δ (same formula)
Extract bit based on quantization interval
frac = (c/Δ) - floor(c/Δ)
bit = 0 if closer to 0.5, 1 if closer to 1.5
Return extracted bit sequence
Simulation of Attacks
The proposed approach, along with baseline approach, was tested with attacks that include:
JPEG Compression (Quality Levels: 30, 50, 70, 90)
Lossy compression that discards high-frequency image data:
30: Heavy compression, significant artifacts
50: Moderate compression, visible artifacts
70: Light compression, minor artifacts
90: Very light compression, nearly lossless
Additive White Gaussian Noise (σ: 2, 5, 10)
Adds random White noise to all pixels with Standard deviation (σ) of noise distribution:
2: Light noise, barely visible
5: Moderate noise, clearly visible
10: Heavy noise, significantly degrades image
Gaussian Blur (Kernel Sizes: 3, 5, 7)
Smooths image by averaging neighboring pixels. Kernel width/height in pixels (odd numbers):
3: Light blurring
5: Moderate blurring
7: Strong blurring, loss of fine details
Rescaling Attacks (0.5, 0.75)
Reduces then enlarges image (loses pixel information) with scaling factors of:
0.5: Shrink to 50% then restore to original size
0.75: Shrink to 75% then restore to original size
Histogram Equalization
Redistributes pixel intensities to enhance contrast by applying standard equalization. Changes in luminance distribution can destroy intensity-based watermarks.
Evaluation Metrics
Mean Squared Error (MSE) [15]
Given two images X and Y (original and watermarked images) each of size M×N:

Peak Signal-to-Noise Ratio (PSNR) [16]
For an image with maximum possible pixel value MAX (e.g., 255 for 8-bit images):
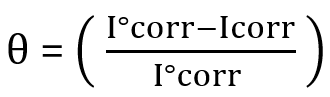
Structural Similarity Index (SSIM) [17,18]
Structural Similarity measures luminance, contrast and structure with values in [-1,1], where 1 indicates identical images.
For local patches (or whole images) X and Y:
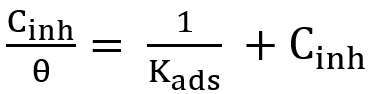
Where, μₓ, μᵧ are means; σₓ², σᵧ² are variances; σₓᵧ is covariance; C₁, C₂ are small stabilizing constants.
Normalized Cross-Correlation (NCC) [19]
Normalized cross‑correlation quantifies similarity between the embedded template/logo and the extracted pattern:
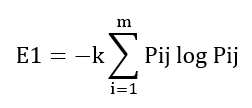
Percent Root-Mean-Square Difference (PRD) is widely used for signal/image distortion [20]:
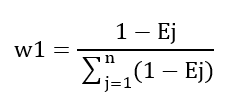
Kullback-Leibler Divergence (KLD): Compares coefficient or feature distributions before/after watermarking (p(i) and q(i)) as an information‑theoretic shift [21,22]:
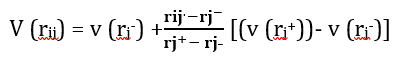
(Usually defined when p(i) > 0 ⇒ q(i) > 0)
Jensen-Shannon Divergence (JSD) a symmetric and bounded variant of KL that is well‑behaved for empirical histograms [23]. For discrete distributions p(i) and q(i), define m(i) = 0.5·(p(i)+q(i)). Then:
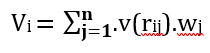
Bit‑Error‑Rate (Ratio) (BER) is the fraction of decoded bits in error after the attack/channel.
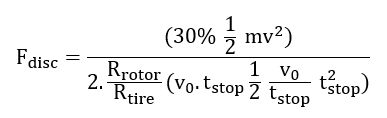
Experimental Setup
The proposed system was tested with images from RSICD (remote‑sensing image captioning dataset) dataset [14] and eight standard publicly accessible images. Thirty-one (from RSICD) plus eight (standard) images across 14 conditions were tested: clean, JPEG (Q=90/70/50/30), AWGN (σ≈2/5/10), Gaussian blur (k=3/5/7), histogram equalization and rescaling (0.75× and 0.5×). Metrics include PSNR and SSIM.
The reported results here were for the proposed scheme and the results reported in Khassaf and Ali [14]. The payload is 8 KB for both approaches. The RSICD images’ dimensions are 224*224 (this cover/carrier image must be sent in Khassaf and Ali [14]), while the eight standard images are 512*512(this cover/carrier image must also be sent in approach presented in Khassaf and Ali [14]).
RSCID Dataset
Figure 3 and 4 and show the watermarked images (for viaduct_399) without and with attacks for the baseline [14] and the proposed approach. Figure 5-7 show the PSNRs and SSIMs calculated for images in RSCID dataset (mean, maximum and minimum values). Figure 8-11 show the PSNRs and SSIMs calculated for four images (namely, airport_259, bridge_291, meadow_52 and park_138) out of the thirty-one images.
Eight Standard Images
Figure 12 and 13 show the watermarked images (for Baboon image) without and with attacks for the baseline [14] and the proposed approach.

Figure 3: Clean and Attacked Stegoimages for the Baseline Approach
Figure 4: Clean and Attacked Stegoimages for the Proposed Approach
Figure 5(a-b): (a) Mean and (b) Maximum PSNR Values for RSCID Dataset for Both Proposed and Baseline Approaches
Figure 6(a-b): (a) Minimum and (b) Mean SSIM Values for RSCID Dataset for Both Proposed and Baseline Approaches
Figure 7(a-b): (a) Maximum and (b) Minimum SSIM Values for RSCID Dataset for Both Proposed and Baseline Approaches
Figure 8(a-b): (a) PSNR and (b) SSIM Values for(airport_259) for Proposed and Baseline Approaches
Figure 9(a-b): (a) PSNR and (b) SSIM Values for (bridge_291) for Proposed and Baseline Approaches
Figure 10(a-b): (a) PSNR and (b) SSIM Values for(meadow_52) for Proposed and Baseline Approaches
The experimental results demonstrate that the RDO-QIM framework can achieve visual quality and robustness metrics comparable to the DWT/DCT-domain baseline [24], with both methods maintaining high fidelity (PSNR>50 dB, SSIM>0.99) across most attack conditions. The most prominent feature of the proposed approach is the full blindness extraction while the baseline approach [14] must send original cover image to achieve the correct extraction and thus achieve the results shown in previous section.

Figure 11(a-b): (a) PSNR and (b) SSIM Values for (park_138) for Proposed and Baseline Approaches
Figure 12: Clean and Attacked Stegoimages for the Baseline Approach
Figure 13: Clean and Attacked Stegoimages for the Proposed Approach
This paper presented a formalized Rate-Distortion Optimized Quantization Index Modulation (RDO-QIM) watermarking framework and provided a comprehensive analysis of its imperceptibility, robustness and computational efficiency. The proposed method successfully integrates rate-distortion optimization into the embedding process, dynamically balancing distortion and payload efficiency while preserving full blindness during extraction, a key advantage over the baseline method which requires the original cover image for detection. Experimental evaluation demonstrated that RDO-QIM consistently outperforms the DWT/DCT- domain baseline in visual quality, achieving an average PSNR exceeding 50 dB and SSIM above 0.99, alongside superior robustness across multiple attack scenarios. Crucially, the proposed scheme maintains this high performance without incurring any side-information transmission overhead, as the embedding strategy relies on a deterministic, key driven process that is perfectly reproducible to the detector. The observed cost is purely computational, arising from the rate- distortion search process.
Future work will focus on accelerating the rate-distortion optimization loop to enhance the scheme practicality for real-time applications. This will be explored through strategies such as coefficient-pruning, heuristic-based adaptive step-size searches and the potential use of lookup tables. Furthermore, we plan to extend the RDO-QIM framework to color and video domains to broaden its applicability. Integrating more advanced, perceptually tuned masking models will also be investigated to improve embedding efficiency and further optimize the trade-off between imperceptibility and robustness. These enhancements will solidify RDO-QIM position as a leading solution for next-generation watermarking in modern multimedia communication systems.
Chen, B.W. et al. “Quantization Index Modulation: A Class of Provably Good Methods for Digital Watermarking and Information Embedding.” IEEE Transactions on Information Theory, vol. 47, no. 4, 2001, pp. 1423-1443. https://doi.org/ 10.1109/18.923725.
Chen, B.W. and G.W. Wornell. “Dither Modulation: A New Approach to Digital Watermarking and Information Embedding.” Proceedings of SPIE, 1999. https://doi.org/ 10.1117/12.344684.
Alomoush, W. et al. “Digital Image Watermarking Using Discrete Cosine Transformation Based Linear Modulation.” Journal of Cloud Computing, vol. 12, 2023. https://doi.org/10.1186/s13677-023-00468-w.
Khafaga, D.S. et al. “Blind Video Watermarking Scheme for Medical Video Authentication.” Heliyon, vol. 9, no. 3, 2023. https://doi.org/10.1016/j.heliyon.2023.e198 09.
“A Reversible-Zero Watermarking Scheme for Medical Images.” Scientific Reports, vol. 14, 2024. https://doi.org/ 10.1038/s41598-024-67672-9.
Li, Hao-Lai et al. “Resampling-Detection-Network-Based Robust Image Watermarking Against Scaling and Cutting.” Sensors, vol. 23, no. 19, 2023. https://doi.org/10.3390/s23 198195.
Pallaw, Vijay Krishna et al. “A Robust Medical Image Watermarking Scheme Based on Nature-Inspired Optimization for Telemedicine Applications.” Electronics, vol. 12, no. 2, 2023. https://doi.org/10.3390/electronics 12020334.
Mokashi, B. et al. “Efficient Hybrid Blind Watermarking in DWT-DCT-SVD with Dual Biometric Features for Images.” Contrast Media & Molecular Imaging, 2022. https://doi. org/10.1155/2022/2918126.
Ali, Musrrat. “Robust Image Watermarking in Spatial Domain Utilizing Features Equivalent to SVD Transform.” Applied Sciences, vol. 13, no. 16, 2023. https://doi.org/10. 3390/app13169515.
Wang, Rui et al. “Separation and Calibration Method of Structural Parameters of 6R Tandem Robotic Arm Based on Binocular Vision.” Mathematics, vol. 11, no. 11, 2023. https://doi.org/10.3390/math11112491.
Yao, Z. and J. Shin. “Cam-UNet: Print-Cam Robust Zero-Bit Fourier Watermarking with Learned Detection.” Sensors, vol. 24, no. 5, 2024. https://doi.org/10.3390/s24 051578.
Schwarz, Alexander P. et al. “Reference gene expression stability within the rat brain under mild intermittent ketosis induced by supplementation with medium-chain triglycerides.” PLOS ONE, vol. 17, no. 10, 2022. https://doi. org/10.1371/journal.pone.0273224.
Wang, Z. et al. “Image Quality Assessment: From Error Visibility to Structural Similarity.” IEEE Transactions on Image Processing, vol. 13, no. 4, 2004, pp. 600-612. https:// doi.org/10.1109/TIP.2004.819861.
Khassaf, N.M. and N.H.M. Ali. “Multilevel Text Protection System Using AES and DWT-DCT-SVD Techniques.” Mesopotamian Journal of CyberSecurity, vol. 5, no. 3, 2025, pp. 913-926. https://mesopotamian.press/journals/ index.php/CyberSecurity/article/view/895.
Pineda-López, F. et al. “A Flexible 12-Lead/Holter Device with Compression Capabilities Based on Compressed Sensing and SPI Interface.” Sensors, vol. 18, no. 11, 2018. https://doi.org/10.3390/s18113773.
Shi, J. et al. “New ECG Compression Method for Portable and Wearable Devices.” Biosensors, vol. 12, no. 7, 2022. https://doi.org/10.3390/bios12070524.
Han, J. et al. Lecture Notes: Kullback-Leibler Divergence. University of Illinois. https://hanj.cs.illinois.edu/cs412/ bk3/KL-divergence.pdf.
Polyanskiy, Y. Lecture Notes: f-Divergences. MIT LIDS. https://people.lids.mit.edu/yp/homepage/data/LN_fdiv.pdf.
Briët, J. et al. Properties of Classical and Quantum Jensen-Shannon Divergence. CWI Report. https://homepages.cwi. nl/~jop/qjsd2.pdf.
Wang, Y. et al. “Multiple Watermarking Algorithms for Vector Geographic Data Based on Multiple QIM.” Applied Sciences, vol. 13, no. 22, 2023. https://doi.org/10.3390/ app132212390.
Qasim, S.R. et al. “A New Nested Hybrid DWT-HD-SVD Watermarking Scheme for Digital Images.” Kufa Journal of Engineering, vol. 15, no. 4, 2024, pp. 65-82. https://doi. org/10.30572/2018/KJE/150406.
Balabantaray, S.K. et al. “An Improved Image Watermarking Technique in Spatial Domain Using Histogram Equalization and Compass Edge Detection with Adaptive Alpha Blending Technique.” 2025 OPJU International Technology Conference (OTCON), 2025, pp. 1-8. https://doi.org/10.1109/OTCON65728.2025.11070 650.
Abbas, N. “Watermarked and Noisy Images Identification Based on Statistical Evaluation Parameters.” Journal of Zankoy Sulaimani - Part A, vol. 15, 2013. https://doi. org/10.17656/jzs.10265.
Lu, X. et al. “Exploring Models and Data for Remote Sensing Image Caption Generation.” IEEE Transactions on Geoscience and Remote Sensing, 2017. https://doi.org/10. 1109/TGRS.2017.2776321.
